READ UNCOMMITTED - 다른 트랜잭션에 의해 수정되었지만 아직 커밋되지 않은 행을 문이 읽을 수 있도록 지정
READ COMMITTED - 다른 트랜잭션에 의해 수정되었지만 아직 커밋되지 않은 데이터를 문이 읽을 수 없도록 지정 - MS-SQL Select : Row 레코드를 읽는 동시에 Lock 을 획득하고, 다음 레코드로 이동하는 순간 Lock 이 해제된다.
REPEATABLE READ - 다른 트랜잭션에 의해 수정되었지만 아직 커밋되지 않은 데이터를 문이 읽을 수 없도록 지정하고 현재 트랜잭션이 완료될 때까지 현재 트랜잭션이 읽은 데이터를 다른 트랜잭션이 수정할 수 없도록 지정 - MS-SQL Select : Row 레코드를 읽는 동시에 Lock 을 획득하고, 최종커밋 또는 롤백 하는 순간 Lock 이 해제된다.
SNAPSHOT - 트랜잭션의 문이 읽은 데이터가 트랜잭션별로 트랜잭션을 시작할 때 존재한 데이터 버전과 일관성이 유지되도록 지정
SERIALIZABLE - 가장 엄격한 격리수준. 트랜잭션이 완료될 때까지 다른 사용자는 그 영역에 해당되는 데이터에 대한 수정 및 입력이 불가능
트랜잭션의 4가지 특징 (ACID)
원자성 (Atomicity)
분해가 불가능한 업무의 최소단위로, 전부 처리되거나, 전부 처리되지 않아야 한다.
일관성 (Consistency)
트랜잭션 결과로 데이터베이스 상태가 모순되지 않아야 한다.
격리성 (Isolation)
트랜잭션의 중간 값에 다른 트랜잭션이 접근할 수 없다.
영속성 (Durability)
트랜잭션의 결과가 데이터베이스에 영속적으로 저장된다.
Lock Escalation - 로우 레벨 Lock 이 페이지, 익스텐트, 테이블 레벨 Lock 으로 점점 확장되는 것. - 오라클은 로우 속성으로 Lock 을 관리하므로, Lock Escalation 이 발생하지 않는다.
동시성 - DML 수행 시, ROW 단위로 배타적 Lock 이 걸린다.
오라클 - DML 문이 실행되는 동안 해당 ROW 는 update/delete 불가하다. select 는 가능.
MS-SQL - DML 문이 실행되는 동안 해당 ROW 는 select/update/delete 불가하다. - 제약조건이나 unique 인덱스 설정이 없으면, insert 하는 동안에 다른 insert 도 가능하다. - insert 하는 동안에, 다른 select 절이 full scan 하게 되면, select 도 동시에 실행이 불가능하다. => index range 스캔을 하게 되면 select 가능.
TX Lock (Transaction Lock) - 행 수준(Row-level) 잠금
TM Lock(Table Lock) - 테이블 잠금, 테이블에 대한 구조적 변경(DDL) 이나, DML(데이터 조작 언어) 작업 시 데이터 무결성을 보장 - SELECT for UPDATE 문 에서도 TM Lock 이 설정된다.
이상현상
Dirty Read - 다른 트랜잭션이 변경중인 데이터를 읽어서 사용했는데. 다른 트랜잭션이 rollback 되는 경우.
Non-Repeatable Read - 한 트랜잭션 내에서 값을 두번이상 읽어서 사용하는 중간에 다른 트랜잭션이 해당값을 변경(update / delete) 해서, 값이 달라지는 경우.
Phantom Read - 한 트랜잭션 내에서 일정 범위의 값을 두번이상 읽어서 사용하는 중간에 다른 트랜잭션이 새로운 값을 추가(insert) 함으로써, 처음 읽을때 없던 값이 나중에 생긴 경우.
비관적 동시성 제어 - 데이터를 읽는 시점부터 Lock 을 설정한다.
낙관적 동시성 제어 - 데이터를 읽는 시점에 Lock 을 설정하지 않는다. - 다만, 읽은 데이터를 다시 읽거나, 수정하는 시점에 반드시 변경 여부를 확인한다.
SELECT FOR UPDATE - 해당 행을 읽으면서, 하단에서 변경하기 위해 lock 을 건다. - Lock 이 걸린 행을 만나면, Lock 이 해제될 때까지 무작정 기다린다.
SELECT FOR UPDATE WAIT n - Lock 이 걸린 행을 만나면, n 초간 기다리고, 해제되지 않으면 SELECT 문 전체를 종료한다. (Exception)
SELECT FOR UPDATE NOWAIT - Lock 이 걸린 행을 만나면, 즉시 SELECT 문 전체를 종료한다. (Exception)
snapshot too old 에러 - Table Full Scan 및 해시 조인을 사용하면 에러를 줄일 수 있다. - 데이터 조회시 Order by 를 사용하면 에러를 줄일 수 있다. - 튜닝을 통해 줄일수는 있어도 완전히 해소하기는 어렵다. - Undo 영역의 크기를 증가시키고, commit 을 자주 수행하지 말아야 한다.
소트 - Sort 양이 많을때 중간 정렬된 집합을 Temp 영역에 저장해둔다. 이 집합을 Sort Runs 라고 한다.
Optimal 소트 - 정렬 대상 집합이 크지 않아 Sort Area 에서 정렬 작업을 완료하는 것
Onepass 소트 - 정렬 대상 집합을 디스크에 한번만 기록하는 것
Multipass 소트 - 정렬 대상 집합을 디스크에 여러번 기록하는 것
Sort 실행계획
SORT (ORDER BY) : Order By 절 SORT (GROUP BY) : Group By 절 + Order By 절 SORT (UNIQUE) : Group By 와 Unique 또는 Distinct 연산, Minus, Intersect, Union 연산 SORT (AGGREGATE) : Count, Avg, Sum, Min, Max 등의 연산 HASH (GROUP BY) : Group By 절
페이징처리 표준 패턴
SELECT * FROM ( SELECT ROWNUM NO, A.* FROM ( /* SQL BODY */ ) WHERE ROWNUM <= (:page * 10) ) WHERE NO >= (:page-1) * 10 + 1
WHERE ROWNUM <= (:page * 10) 절에 의해 top n stopkey 알고리즘이 적용된다. 부분 범위처리 가능
First Row Min/Max - min/max 연산을 사용할때, 조건절와 min/max 컬럼값이 모두 인덱스에 있어야 효율적이다. - First Row Min/Max 이 안되는 경우, order by 와 rownum <= 절로 변경하는것이 효율적이다.
DML 성능에 영향을 미치는 요소 - 인덱스, 무결성제약, 조건절, 서브쿼리, redo/undo 로깅, Lock, 커밋
Array Processing기능 - 한 번의 SQL 수행으로 다량의 로우를 동시에 insert/update/delete - 네트워크 부하를 줄이고, 데이터베이스 Call 횟수를 줄여준다. - OLTP 시스템에서 성능 개선
Direct Path Insert - 버퍼캐시를 거치지 않고, 작업 데이터파일에 기록 - Exclusive 모드 TM Lock 을 설정 - Freelist 를 참조하지 않고 HWM 바깥 영역에 데이터를 순차적으로 입력 - Undo 로깅을 최소화
alter table tablename nologging; // redo 로그를 생성하지 않음 : insert 에서만 작동 insert /*+ append */ into tablename // Direct Path Insert 작동 select * from sourcetable;
Recursive Call 은 Parse Call / Execute Call / Fetch Call 단계에서 모두 나타날 수 있다. Array Size 를 늘리면, Fetch Call 을 줄일 수 있다. Array Processing 을 늘리면, Execute Call 을 줄일 수 있다.
병렬처리 Insert
인덱스 비활성화 / 활성화 alter index PK_index_name on tablename DISABLE; alter index PK_index_name on tablename ENABLE;
Merge Into 사용법
Merge Into 고객 c Using 고객 d On ( c.법정대리인_고객번호 = d.고객번호 and c.성인여부 = 'N' ) when matched then -- update set c.법정대리인연락처 = d.연락처 when not matched then -- insert (col1, col2) values (d.col1, d.col2) ;
대용량 데이터 UPDATE 튜닝 - update 구문을 truncate / insert 로 대체
update 주문 set 상태코드 = '9999'
=>
create table tmp as select * from 주문; truncate table 주문; insert into tmp select ..., '9999' as 상태코드, ... from tmp; drop table tmp;
어플리케이션 커서를 캐싱 하면, Parse Call 이 1번만 나타난다. Array Size 를 늘리면, Fetch Call 이 줄어든다 : fetch call * array size = rows Array Processing 을 하면, Execute Call 을 줄인다.
DB저장형 사용자정의 함수/프로시저 - 가상머신 상에서 실행되는 Interpreting 언어다. - 함수가 실행될때마다 Recursive Call 이 발행한다. - Join 대신, 함수를 사용하여 코드명 등을 조회하면, 성능이 나빠진다.
DB저장형 함수 성능개선 - Join 문으로 변경 - Deterministic 함수로 전환 - Result 캐시 사용
DB저장형 함수 Recursive Call 횟수 개선 - 1. 함수 호출을 스칼라 서브쿼리로 변환한다 (스칼라 서브쿼리 캐싱) : ( select code_nm(1, 2) from dual ) cd_name - 2. Deterministic 함수 캐싱 - 3. Result 캐시 - 4. Native 컴파일
파티셔닝 (Partitioning) - 테이블데이터 또는 인덱스 데이터를 나누어서 저장하는 기능 - 다른 파티션에 대량 변경/백업/복구 중에도, 조회/변경/삭제 가능
Range 파티션 - 여러 컬럼 지정 가능 - 숫자,문자,날짜 컬럼 사용 가능 - 범위에 없는 값이 들어왔을 때 오류를 방지하기 위해 MAXVALUE 파티션을 사용해야 한다. - 신규 파티션을 추가해야 하는 관리 이슈가 있다.
partion by range(주문일시) ( partition p20201 values less than( to_date('20200701', 'YYYYMMDD') ), partition p20202 values less than( to_date('20210101', 'YYYYMMDD') ), partition p20211 values less than( to_date('20210701', 'YYYYMMDD') ), partition p20212 values less than( to_date('20220101', 'YYYYMMDD') ), partition pMAX values less than( MAXVALUE ) )
List 파티션 - 단일 컬럼만 지정 가능 - 불연속적인 값의 목록으로 분할할때 사용 - 범위에 없는 값이 들어왔을 때 오류를 방지하기 위해 DEFAULT 파티션을 사용해야 한다.
Pruning - SQL 파드파싱이나 실행시점에 조건절을 분석해서, 읽지말아야 할 파티션을 제외하는 기능 - 문자형 날짜값에 Like 조건을 사용하면 불필요한 파티션을 읽게 된다. Between 조건으로 변경하는것이 좋다. - 문자형 날짜값에 숫자로 검색하면, 형변환이 발생해 전체 파티션을 조회하게 된다. - 정적 Pruning / 동적 Pruning 성능 차이는 없다.
PARTITION RANGE ALL - 파티션 컬럼을 가공하면, 파티션 Pruning 이 불가능 해, 전체 파티션을 조회 하게 된다. - 파티션 컬럼 조건에 다른 타입의 값을 넣을경우, 강제 형변환이 발생하여, 전체 파티션을 조회 할수 있으니 주의해야 한다.
정적(Static) 파티션 Pruning - 조건절에 파티션 키 컬럼이 상수로 들어있는 경우 - 쿼리 최적화 시점에 액세스할 파티션 번호를 알 수 있다. - 실행계획 Pstart, Pstop 에 파티션 번호가 표시된다.
동적(Dynamic) 파티션 Pruning - 조건절에 파티션 키 컬럼이 바인드 변수로 들어있는 경우, 다른 테이블과의 Join 조건일 경우. - 실행 시점에 액세스할 파티션을 알 수 있다. - 실행계획 Pstart, Pstop 에 KEY 라고 표시된다.
Partition Index - Local Partition Index 와 Global Partition Index 로 구성된다.
Local Partition Index - 파티션 테이블 내의 데이터로만 인덱스가 구성된다. - Prefixed Index 와 Non-Prefixed Index 로 구성된다. - 테이블 파티션을 재구성하면, Local Index 는 자동으로 Rebuild 되어 관리의 편의성이 있다.
create index dept_local_ix1 on dept(deptno) LOCAL;
Local Prefixed Index - 파티션 컬럼이 인덱스 인 경우 (인덱스가 여러 컬럼일때 선두 컬럼)
Local Non-Prefixed Index - 인덱스된 컬럼이 파티션 컬럼이 아닌 경우 (인덱스가 여러 컬럼일때, 선두 컬럼이 파티션 컬럼이 아닐 때)
Global Partition Index - 파티션 테이블과는 별도로 인덱스 파티션 규칙으로 파티션을 구성한다. - Non-Partition Table 에도 생성 가능하다. - Prefixed Index 만 존재한다. (Non-Prefixed Index 불가) - 테이블 파티션을 재구성하면, Index Unusable 상태가 되어, Rebuild 가 필요하다.
create index sales_global_ix1 on sales (cust_nm) GLOBAL partition by hash (cust_nm) partitions 4;
Index Unusable(IU) 상태 - Partition Index / Non-Partition Index 가 사용불가 상태가 되는 경우. - IU 파티션을 사용하려고 하면 오류가 발생한다. IU 파티션을 Rebuild 해야 한다. - 1. Direct Path Load 시 index 가 해당 테이블 data 보다 이전것인 경우 - 2. Alter Table Move Partiton : ROWID 를 변화시키는 작업 - 3. Alter Table Truncate Partition / Drop Partition 과 같은 테이블의 행을 지우는 작업 - 4. Alter Table Split Partition - 5. Alter Index Split Partition
배치(Batch) 프로그램 - 일련의 대량 작업을 묶어서 일괄 처리
배치프로그램 튜닝 - 전체 처리속도 최적화에 목표 - Array Processing 을 활용 - 임시 테이블을 활용 - 병렬처리를 적절히 활용. 단, 필요 이상의 병렬도(DOP) 를 지정하지 않아야 한다.
병렬처리 - 병렬 처리란 SQL문이 수행해야 할 작업 범위를 여러 개의 작은 단위로 나누어 여러 프로세스가 동시에 처리
QC(Query Coordinator) - 병렬 SQL문을 발행한 세션 - 병렬 서버 집합을 할당 - 각 병렬 서버에게 작업을 할당 - 병렬로 처리하도록 사용자가 지시하지 않은 테이블은 QC가 처리
Intra-Operation Parallelism - 병렬 처리에서 서로 배타적인 범위를 독립적으로 동시에 처리하는 것
Inter-Operation Parallelism - 프로세스 간의 통신을 뜻한다. - 다른 서버집합에 분배하거나 정렬된 결과를 QC에서 전송하는 작업을 병렬로 동시에 진행하는 것 - 병렬도(DOP) 의 2배의 프로세스가 필요하고, 병렬도(DOP) 의 제곱만큼 파이프 라인(테이블 큐)이 필요
S->P (Parallel from Serial) - QC가 읽은 데이터를 테이블 큐를 통해 모든 병렬 서버 프로세스에게 전송 - BROADCAST 라고 표시하며, Inter-Operation Parallelism 에는 속하지 않는다. - 데이터 크기가 작을수록 유리
P->S (Parallel to Serial) - 각 병렬 서버 프로세스가 처리한 데이터를 QC에게 전송하는 것 - Inter-Operation Parallelism 에 속한다. - order by가 있을 때는 QC(ORDER) - order by가 없을 때는 QC(RANDOM)
P->P (Parallel to Parallel) 오퍼레이션 - 한 서버 집합이 반대편 서버 집합에 데이터를 전송하는 것 - 데이터를 재분배하는 오퍼레이션으로 데이터를 정렬하거나 그룹핑, 조인을 위한 동적으로 파티셔닝을 할 때 발생 - Inter-Operation Parallelism 에 속한다.
PCWP (Parallel Combined with Parent) - 한 서버 집합이 현재 스텝과 그 부모 스텝을 모두 처리 - Intra-Operation Parallelism 에 속한다.
PCWC (Parallel Combined with Child) - 한 서버 집합이 현재 스텝과 그 자식 스텝을 모두 처리 - Intra-Operation Parallelism에 속한다.
parallel_index - 블록 기반 Granule : Full Table Scan 일때는 병렬도(DOP) 를 파티션 사이즈보다 크게 지정할 수 있다. - 파티션 기반 Granule : Index Range Scan 일때는 병렬도(DOP) 를 파티션 사이즈만큼 지정해야 효율적이다.
Hint
PARALLEL - 병렬 처리 하도록 한다. - PARALLEL(table, dop) - 반드시 FULL 힌트를 같이 사용한다.
PARALLEL_INDEX - 인덱스 범위 스캔을 병렬로 처리 - PARALLEL_INDEX(table, index, /* dop */) - 반드시 INDEX 또는 INDEX_FFS 힌트를 같이 사용한다.
group by / order by / hash join 을 사용하면, 병렬프로세스가 dop 의 2배 만큼 필요하다.
PQ_DISTRIBUTE - 병렬 Join 시에 데이터 분배 방식을 직접 결정 - PQ_DISTRIBUTE(inner_table, outer_distribution, inner_distribution)
pq_distribute(inner_table, hash, hash) - 병렬조인을 위해 해시함수를 사용하도록 지정 - 실행계획에 PX SEND HASH 가 나타난다.
pq_distribute(inner_table, broadcast, none) - outer table 의 모든 데이터를 병렬서버에 전송 - outer table 의 데이터 크기가 작을때 사용 - 실행계획에 PX SEND BROADCAST 가 나타난다.
pq_distribute(inner_table, none, broadcast) - inner table 의 모든 데이터를 병렬서버에 전송 - inner table 의 데이터 크기가 작을때 사용 - 실행계획에 PX SEND BROADCAST 가 나타난다.
pq_distribute(inner_table, partition, none) - Partial Partition-wise Join - inner table 이 조인 키 컬럼에 대해 파티셔닝 돼 있을 때 사용 - 실행계획에 PX SEND PARTITION 이 나타난다.
pq_distribute(inner_table, none, partition) - Partial Partition-wise Join - outer table 이 조인 키 컬럼에 대해 파티셔닝 돼 있을 때 사용 - 실행계획에 PX SEND PARTITION 이 나타난다.
pq_distribute(inner_table, none, none) - Full Partition-wise Join - join 되는 두 테이블 모두 Join Key 컬럼으로 파티션되어 있는 경우에 사용 - 실행계획에 PX PARTITION RANGE ALL 이 나타난다. - 하나의 서버 집합만 필요.
ROWNUM - 병렬처리 쿼리에 ROWNUM 을 사용하면, 병렬프로세스에 병목이 발생한다.
rownum 을 row_number() 바꿔서 사용해야 한다.
select rownum() as 일련번호, 주문일자, 순번 from ( select /*+ parallel(t_order 4) 주문일자, 순번 from t_order order by 주문일자, 순번 ) => select /*+ parallel(t_order 4) row_number() over(order by 주문일자, 주문순번) as 일련번호, 주문일자, 순번 from t_order
데이터 복제 기법
데이터 복제를 이용한 소계 구하기 - 카티션 곱(Cartesian Product) 을 이용
select rownum as no from dual connect by level <= 2;
1 2
select deptno 부서번호 , decode(no, 1, to_char(empno), 2, '부서계') 사원번호 , sum(sal) 급여합 , round(avg(sal)) 급여평균 from emp e, (select rownum as no from dual connect by level <= 2) group by deptno, no, decode(no, 1, to_char(empno), 2, '부서계') order by 1, 2;
unpivot (열데이터를 행데이터로 변환)
SELECT * FROM 테이블 UNPIVOT ( 컬럼별칭(값) FOR 컬럼별칭(열) IN (피벗열명 AS '별칭', ... )
select 고객번호, 고객명, 연락처구분, 연락처번호 from 고객 unpivot ( 연락처번호 for 연락처구분 in ( 집전화번호 as '집전화번호' , 사무실전화번호 as '사무실전화번호' , 휴대폰번호 as '휴대폰번호' ) ) where 고객구분코드 = 'VIP'
pivot (행데이터를 열데이터로 변환)
SELECT * FROM 테이블 PIVOT ( 집계함수 FOR 대상필드 IN (필드값 목록) )
select C.고객번호, C.고객명, D.집, D.사무실, D.휴대폰 from 고객 C , 고객연락처 pivot ( min(연락처번호) for 연락처구분코드 in ( 'HOM' as '집', 'OFC' as '사무실', 'MBL' as '휴대폰' ) ) D where C.고객번호 = D.고객번호 and C.고객구분코드 = 'VIP'
LISTAGG
행을 문자열로 합치는 기능 (pivot)
LISTAGG([합칠 컬럼명], [구분자]) WITHIN GROUP(ORDER BY [정렬 컬럼명]) (하단에 group by 사용시)
LISTAGG([합칠 컬럼명], [구분자]) WITHIN GROUP(ORDER BY [정렬 컬럼명]) OVER(PARTITION BY [그루핑 컬럼명]) (하단에 group by 미사용시)
분석함수 : 누적값
sum(매출금액) over(partition by 지점코드 order by 판매월 range between unbounded preceding and current row) ) 누적매출
부등호조인 : 누적값
select A.지점코드, A.판매월, min(A.매출금액) 매출금액 , sum(B.매출금액) 누적매출 from 월별지점매출 A, 월별지점매출 B where A.지점코드 = B.지점코드 and A.판매월 >= B.지점코드 group by A.지점코드, A.판매월 order by A.지점코드, A.판매월
with 구문 (CTE)
materialize 방식 - 임시 테이블을 사용하여 반복 재사용, 실행계획에 TEMP TABLE TRANSFORMATION 이 나타남. - 사이즈가 큰 데이터를 읽어 GROUP BY, 조인 등으로 집합크기를 줄일 수 있을때 사용. - /*+ materialize */
비용기반 옵티마이저 (CBO) - 통계정보 : 데이터양, 컬럼값의 수, 컬럼값 분포, 인덱스 높이, 클러스터링 팩터, 최대값, 최소값, NULL개수, 히스토그램 등 - 시스템 통계정보 : CPU속도, Single Block I/O 속도, Multi Block I/O 속도, Multi Block 개수 등 - 통계정보를 사용해서 실행계획을 세운다. - 실행계획 선택에 대한 내부 규칙이 있다. - 효율적이다. - 버퍼 캐싱 효과는 고려하지 않는다. (디스크 I/O 를 기준으로 한다.)
규칙기반 옵티마이저 (RBO) - 통계정보를 전혀 사용하지 않고, 단순히 규칙에만 의존한다. - 대량 데이터 처리에 적합하지 않다. - 인덱스 구조, 연산자, 조건절의 형태로 우선순위 규칙에 따라 최적화 한다. - 인덱스가 있으면 무조건 인덱스를 사용한다. : Full Table Scan 이 우선순위가 가장 낮다. - 부등호보다 between 이 우선순위가 높다.
옵티마이저 서브엔진 - Query Transformer : 쿼리 변환 과정 - Estimator : 예상 비용 산정 - Plan Generator : 실행계획 후보군 생성
스스로 학습하는 옵티마이저 (Self Learning Optimizer) - Adaptive Cursor Sharing : 바인드변수에 따라 실행계획을 선택적으로 사용 - Statistics Feedback : 실행계획의 로우수와 실제 로우수가 다를때, 다음번에 이전 로우수에 따른 실행계획이 수립되도록 함 - Adaptive Plans : 런타임에 실행계획을 변경
최적화
전체 처리속도 최적화 (ALL_ROWS) - 전체를 읽기 때문에 시스템리소스(I/O, CPU, 메모리) 를 적게 사용하는 실행계획을 선택
최초 응답속도 최적화 (FIRST_ROWS, FIRST_ROWS_N) - 응답속도가 빠른 실행계획을 선택 - 2-Tier 클라이언트/서버 구조 : 커서를 오픈해서 데이터를 Fetch 하다가 중간에 멈출 수 있는 기능 - 인덱스를 많이 선택하고, 해시조인보다 NL 조인을 더 많이 선택한다.
SQL 최적화 과정 - 테이블, 컬럼, 인덱스 정보, 각각 통계 정보를 사용한다. - 시스템 통계정보(CPU 속도 등) 을 사용한다. - 옵티마이저 관련 파라미터 사용 - 통계 정보를 사용한다. 통계 정보를 저장하지는 않는다.
SQL 파싱과 최적화 순서 1. Parser : SQL 개별 구성요소를 분석해서 파싱트리를 만든다. 2. Query Transformer : SQL 을 일반적이고 표준적인 형태로 변환 3. Plan Generator & Estimator : 실행 후보군을 도출하고, 비용을 계산 4. Row-Source Generator : SQL 엔진이 실행할 수 있는 프로시저 형태로 포매팅
SQL 파싱 - 소프트파싱 : SQL 이 라이브러리 캐시에 존재하면 이를 사용하여 실행 - 하드 파싱 : SQL 이 라이브러리 캐시에 존재하지 않으면 최적화 및 로우 소스 생성 단계까지 모두 거쳐서 실행
선택도(Selectivity) - 조건절에 의해 선택될 것으로 예상되는 레코드 비중 : 1 / NDV
카디널리티(Cardinality) - 조건절에 의해 선택될 것으로 예상되는 레코드 수 : 전체레코드수 * 선택도
I/O 비용 모델의 비용(Cost) - 예상되는 디스크 I/O Call 횟수
CPU 비용 모델의 비용(Cost) - 예상소요시간을 Single Block I/O 횟수로 환산한 값
서브쿼리 - 하나의 SQL 문장에서 괄호로 묶은 별도의 쿼리 블록
인라인 뷰 - FROM 절에 나오는 서브쿼리로 레코드를 선택하는 쿼리다.
중첩된 서브쿼리 - WHERE 절이나 HAVING 절과 같은 조건절에서 사용되는 서브쿼리로, 메인 쿼리의 데이터를 필터링하거나 비교할 때 사용
스칼라 서브쿼리 - 주로 SELECT 절이나 다른 쿼리의 일부로서 단일 값을 반환하는 서브쿼리
no_unnest - 중첩된 서브쿼리를 각각 그대로 FILTER 방식으로 처리한다. - 서브쿼리의 결과가 작을 때 유리하다. : 캐싱 - 조건절의 스칼라 서브쿼리 : 실행계획에 FILTER 로 나타나게 된다.
unnest - 중첩된 서브쿼리를 풀어낸다. - 조건절의 스칼라 서브쿼리 : 실행계획에 NL 조인으로 나타나게 된다. - unnest 를 사용하게 되면, rownum 조건을 제거해야 한다.
use_concat - OR 조건을 union all 로 변환해준다.
- where job = 'cleark' or deptno = 20 => ... where job = 'cleark' union all ... where deptno = 20
no_expand - OR 조건을 union all 로 변환하지 않고 그대로 수행하도록 한다.
merge - 뷰머징 : 인라인뷰를 해체하여 상위 쿼리로 올린다.
no_merge - 인라인뷰를 해체하지 않고 그대로 수행
push_subq - 일반적으로, 조건절의 FILTER 조건인 서브쿼리는 제일 마지막에 실행된다. - push_subq 를 사용하면, FILTER 조건인 서브쿼리를 먼저 실행되도록 한다. - /*+ no_unnest push_subq */
- 랜덤 액세스 위주의 조인 방식 : 대량 데이터에서 불리 - 소량데이터 조인시 유리 - DB버퍼캐시에서 읽으므로, 블록에 래치 획득 및 체인 스캔 과정을 거친다. : 대량 데이터에서 불리 - 인덱스를 이용한 조인으로, 인덱스 구성 전략에 의해 성능이 크게 달라진다. - 후행 테이블의 인덱스 효율성이 중요하다. - 소량 데이터에 유리, OLTP 시스템에 적합 - 한 레코드씩 순차적으로 진행 : "부분범위 처리"가 가능 - 조인 대상 레코드가 많아도, ArraySize 에 해당하는 최초 n 건을 빠르게 출력 가능
소트머지조인 - 실시간으로 인덱스를 생성한다. - 첫번째 집합은 조인컬럼에 인덱스가 있으면 인덱스를 사용하고, 없으면 PGA 영역에 저장한다. - 두번째 집합은 정렬해서 PGA 영역에 저장한다. - 조인조건이 = 이 아닐때, 조인조건이 없을때도 사용가능하다. - 버퍼영역이 아닌 PGA 영역에서 조회하므로, 대량 데이터에서 NL 조인보다 빠르다. : 래치 획득 과정이 없어서
Hash 조인 - 작은 집합을 읽어서 PGA 에 해시맵으로 저장한다. - 해시맵을 사용하여 탐색하기 때문에 조인컬럼에 인덱스가 없어도 상관이 없다. : 인덱스가 성능에 영향을 주지 않음 - 소트머지조인보다 Temp테이블스페이스 사용량이 적다. - 해시키로 조회하므로 조인 조건이 = 일때만 사용가능하다. - 양쪽 모두 대량 데이터에서 NL 조인보다 빠르다. - 수행빈도가 낮고, 쿼리 수행시간이 오래 걸리는 대량 데이터 조인시 유리하다. - DW/OLAP / Batch 프로그램에 사용.
join 힌트
Oracle
ordered
/*+ ordered */ - FROM 절에 나열된 순서대로 조인
leading
/*+ leading(a b c) */ - a b c 순서대로 조인
use_nl( a ) - NL 조인 힌트
use_hash( a ) - 해시 조인 힌트
use_merge( a ) - 소트 머지 조인 힌트
nl_sj - NL 세미조인 : 서브쿼리에서 사용
swap_join_inputs( a ) - a 를 build input 으로 한다. (조인의 첫번째 집합) : 해시조인에서 사용
no_swap_join_inputs ( a ) - a 를 probe input 으로 지정한다. (조인의 두번째 집합) : 해시조인에서 사용
NO_MERGE - 메인쿼리와 인라인뷰를 병합하지 말고, 인라인뷰부터 실행한다. : 인라인뷰에 함수 등이 쓰일때, 한번만 실행하도록 유도
NO_UNNEST - 서브쿼리를 필터 방식으로 동작하도록 처리 : 부분범위 처리가 가능해서, 해시 조인으로 처리되던거를 NL 조인으로 변경이 된다.
FULL - 테이블 풀 스캔
PUSH_SUBQ - 서브쿼리가 먼저 실행되도록 제어
QB_NAME( name ) - 현재 쿼리블록의 이름을 지정
index(table index) - table 의 index 를 사용하도록 한다.
index_desc - 인덱스를 역순으로 사용
index_ffs - 인덱스 Fast Full Scan 사용
use_concat - Concatenation 오퍼레이션 : OR 조건을 풀어서, Union All 조건의 쿼리로 변환한다. : or_expand
no_expand - use_concat 이 작동하지 않도록 한다. : no_or_expand
MS-SQL
force order
option( merge join) - FROM 절에 나열된 순서대로 조인
merge join option( merge join ) - 소트 머지 조인 힌트
loop join - NL 조인 힌트
inner loop join
from A inner loop join B on A.col1 = B.col2
inner hash join
스칼라 서브 쿼리
- 스칼라 서브 쿼리는 단일 값만을 반환해야 한다. (스칼라) - 오라클에서는 서브쿼리 입출력값을 내부캐시에 저장해 두기 때문에 성능향상에 좋다. - 서브쿼리의 효율은 코드명이나 상품명을 변환시 사용 : 카디널러티가 적은 테이블에 사용하면 좋다.
스칼라 서브쿼리 Execution Plan - 서브쿼리가 위에 나오고, 메인쿼리가 아래에 나온다.
부분범위처리 - 조건을 만족하는 전체범위를 처리하는 것이 아니라 일단 운반단위(Array Size) 까지만 처리 하여 추출하는 처리방식 - TOP n / ROWNUM 사용 등 - 인덱스 사용이 가능하도록 조건절을 구사하고, 조인은 NL위주로 처리하고, Order By절이 있어도 소트연산을 생략할 수 있도록 인덱스를 구성 : index 의 2번째 컬럼부터 order by 컬럼을 추가 - 페이징 처리 (게시판 등)
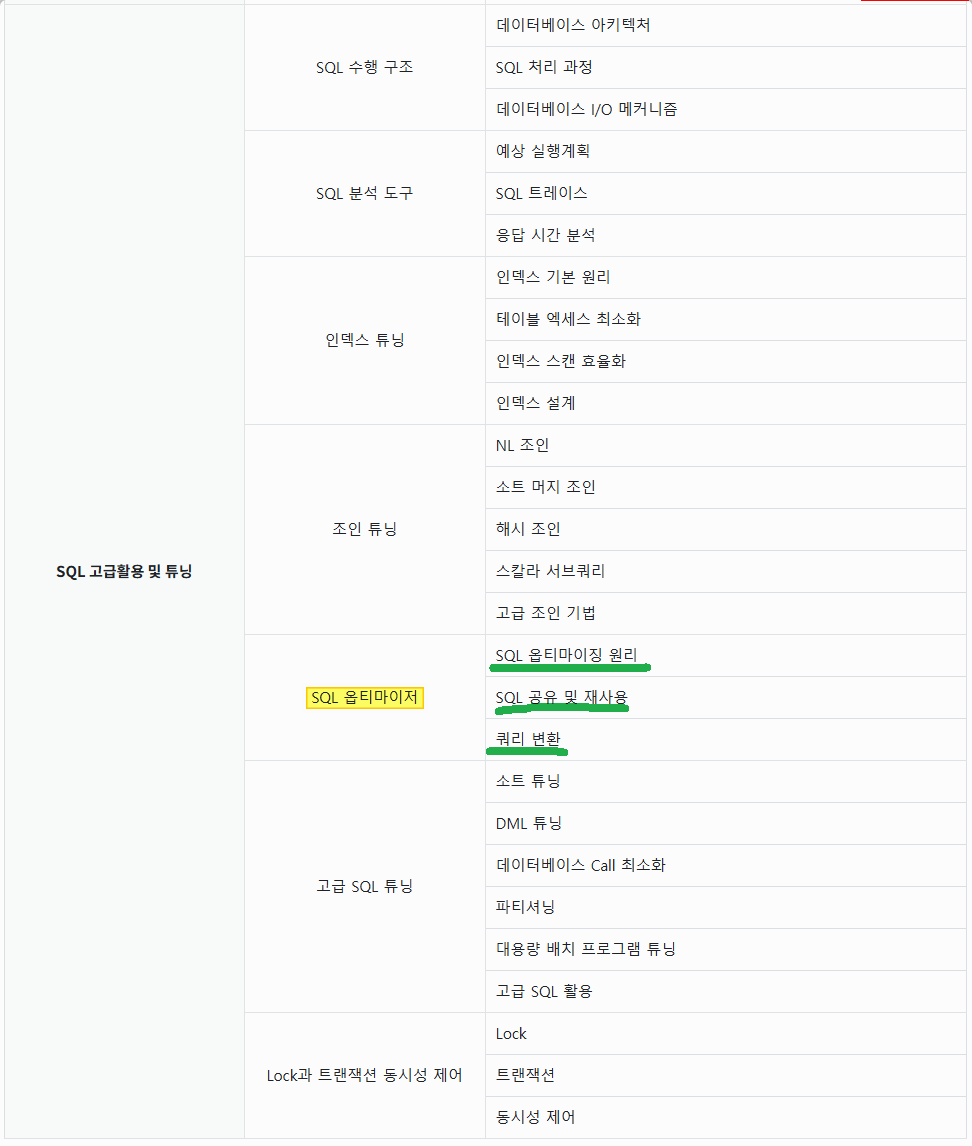
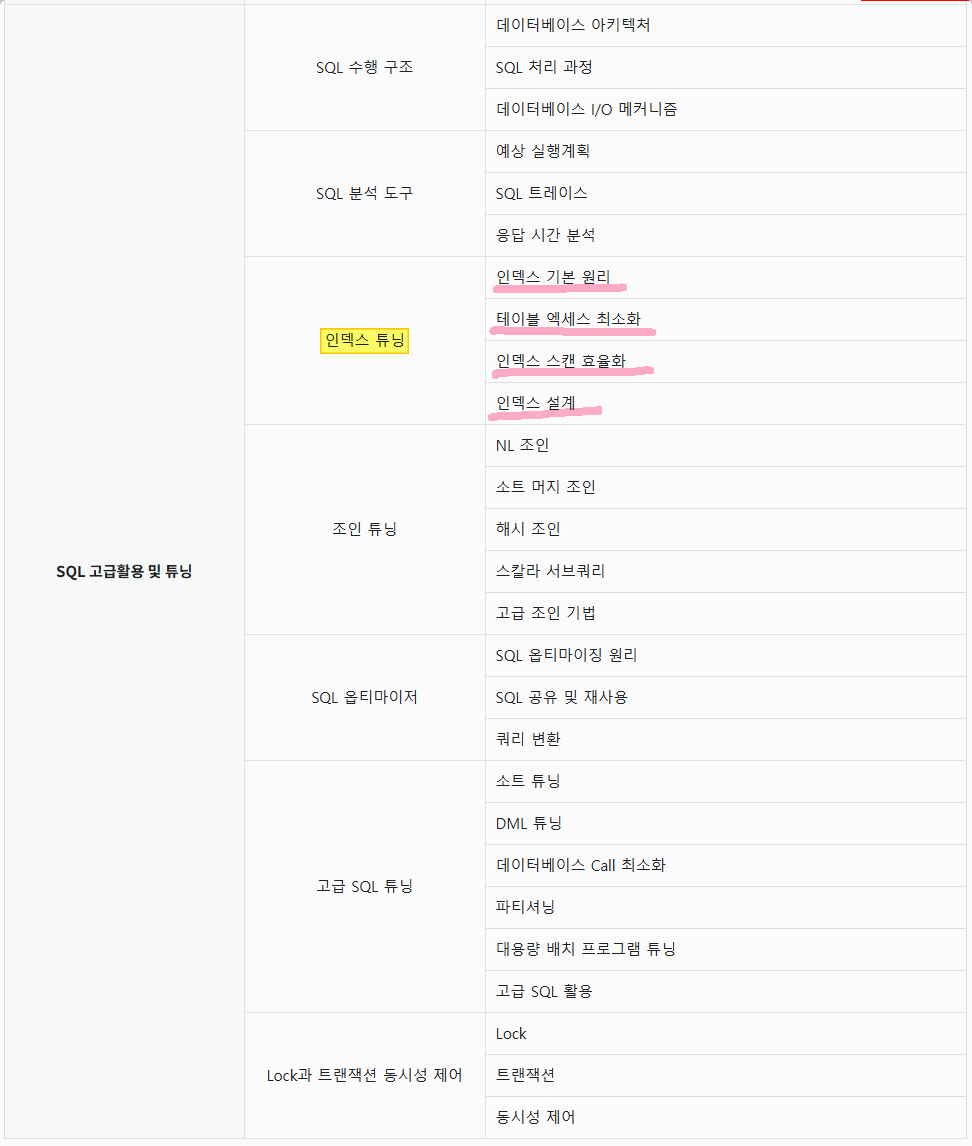
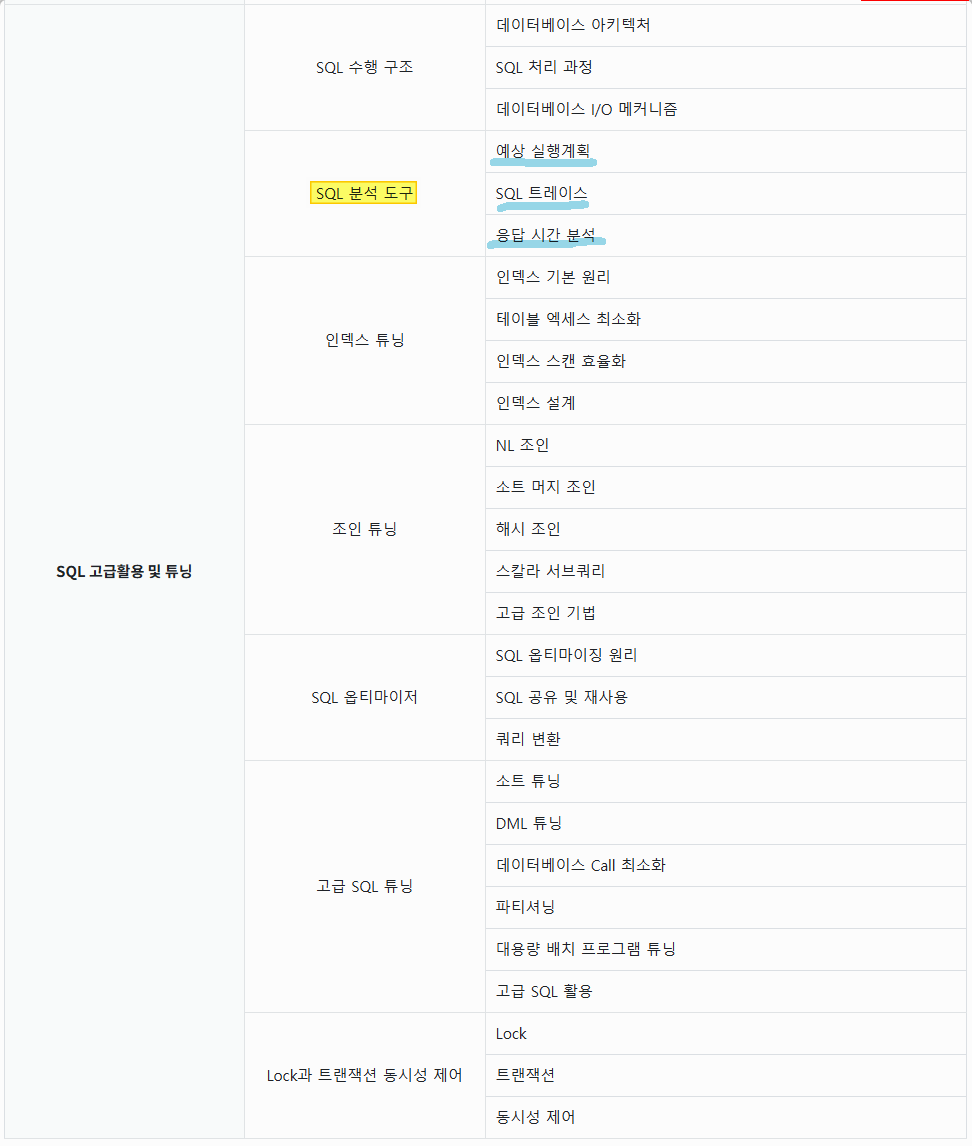
1. SQL 수행 구조 2. SQL 분석 도구 3. 인덱스 튜닝 4. 조인 튜닝 5. SQL 옵티마이저 6. 고급 SQL 튜닝 7. Lock과 트랜잭션 동시성 제어
B*Tree 인덱스 (Balanced Tree) 구조 - 브랜치 블록의 각 로우는 하위블록에 대한 주소값을 갖는다. - 리프 블록의 키 값은 테이블 로우의 키 값과 같다. - 리프 블록 끼리는 이중연결리스트(double linked list) 구조이다.
인덱스 ROWID - (오브젝트번호 + ) 데이터파일번호 + 블록번호 + 블록내로우번호 - 데이터파일 상의 블록 위치를 가리킨다. 논리적인 주소 (물리적인 주소는 아니다.) - 버퍼 캐시에서 찾을때는 해시 알고리즘을 이용한다.
인덱스 클러스터링 팩터 - 인덱스에 저장된 순서와 테이블에 저장된 데이터의 저장 순서가 얼마나 일치하는지를 나타내는 값 - 최대값은 인덱스에 저장된 항목의 개수 - 최소값은 테이블 블록의 개수
테이블 블록 수에 가까울수록 좋고, 테이블 레코드 수에 가까울수록 나쁘다.
인덱스 클러스터링 팩터가 좋으면, 테이블 액세스 단계에서 읽어들이는 블록(데이터) 가 줄어든다. 인덱스 리빌드 해도 클러스터링 팩터가 좋아지지 않는다. 테이블을 재생성 해야 한다.
인덱스에는 구성 컬럼값이 모두 NULL 인 값은 저장하지 않는다.
IOT (index organizaion table) - Table Random 엑세스가 발생하지 않도록 테이블을 아예 인덱스 구조로 생성 - PK 순으로 정렬상태를 유지한다. - IOT 테이블의 일반 인덱스에는 PK 컬럼도 함께 저장된다.
- MS-SQL 의 Clustered Index 와 유사한 개념
인덱스 스캔 방식
Index Range Scan - 인덱스 루트에서 리프 블록까지 수직적 탐색을 하고, 필요한 범위만큼 수평적 탐색하는 스캔 방식 - 인덱스 선두컬럼이 조건절에 있어야 한다.
Index Unique Scan - 수직적 탐색으로만 데이터를 찾는 스캔 방식 - 인덱스 컬럼이 모두 조건절에 있는 경우( = 조건)
Index Skip Scan - 루트 또는 브랜치 블록에서 읽은 컬럼 값 정보를 이용해서 조건절에 부합하는 레코드를 포함할 가능성이 있는 리프 블록만 액세스 - 인덱스 선두 컬럼이 조건절에 없어도 인덱스를 활용하는 새로운 스캔 방식 - 조건절에 빠진 선행 인덱스 컬럼의 Distinct Value 개수가 적고, 후행 컬럼의 Distinct Value 개수가 많을 때 유용 (선행컬럼이 datetime 일때는 불리, 날짜값(년월일)만 있을때 유리)
- 힌트 : index_ss - 선두 컬럼이 부등호, between, like 같은 범위 조건일때도 사용 가능 - 선두 컬럼이 in ( list ) 조건일때는 사용 불가
Index Full Scan - 수직적 탐색 없이 인덱스 리프 블록 처음부터 끝까지 수평적으로 탐색하는 방식 - 인덱스 힌트 사용하고, 해당 인덱스의 선두컬럼이 조건절에 없는 경우 사용된다. - 인덱스 필터 조건을 만족하는 데이터가 적어야 효과적이다.
Index Fast Full Scan - 논리적인 인덱스 트리 구조를 무시하고, 인덱스 세그먼트 전체를 Multiblock I/O 방식으로 스캔 - 물리적으로 디스크에 저장된 순서대로 인덱스 리프 블록을 읽음. - 결과 레코드의 순서는 실제 데이터 순서와 다르게 나옴 - 힌트 : index_ffs
Index Range Scan Descending - Index Range Scan과 기본적으로 동일한 스캔, 인덱스를 뒤에서부터 앞쪽으로 스캔 - 힌트 : index_desc
인덱스 컬럼의 가공 - 인덱스 컬럼이 가공되면, index range scan 이 불가해 진다. - 부정형 비교는 index range scan 이 불가하다. - is not null 조건은 index range scan 이 불가하다.
where substr(업체명, 1, 2) = '대한' => where 업체명 like '대한%'
where 월급여 * 12 = 36000000 => where 월급여 = 36000000 / 12
묵시적 형변환
문자와 숫자를 비교하는 경우, 자동으로 숫자로 형변환이 일어난다.
where 숫자형DeptNo = '20' => 숫자형DeptNo = to_number('20') 로 형변환이 일어나고, 인덱스 사용 가능
where 문자형DeptNo = 20 => to_number(문자형DeptNo) = 20 로 형변환이 일어나고, 인덱스 사용 불가
테이블 Random 액세스
인덱스 Leaf 노드에는 ROWID 가 있어, 인덱스에 없는 컬럼을 참조시, 테이블 ROWID 로 Random 액세스를 하게 된다.
실행계획에는 아래와 같이 표시된다.
TABLE ACCESS (BY INDEX ROWID) OF '테이블명' (TABLE)
테이블 랜덤 액세스가 많아지면, 전체 테이블 스캔(Full Table Scan) 보다 느려질 수 있다. (인덱스 손익 분기점)
배치 I/O - 테이블 랜덤 액세스시, 버퍼에서 블록을 찾지 못하면, 디스크에서 읽게 된다. 이때, 매번 디스크에서 읽지 않고, 모았다가, 일괄로 찾아오는 방법으로 I/O 효율을 높이는 방법이다.
배치 I/O 가 수행되면, 랜덤 액세스 방식이 아래처럼 변경된다.
TABLE ACCESS BY INDEX ROWID => TABLE ACCESS BY INDEX ROWID BATCHED
배치 I/O 가 수행되면, 버퍼에 없는 블록끼리 모아서 처리 되므로, 결과집합의 정렬 순서가 바뀌게 되고,
실행결과에 SORT ORDER BY 가 나타나면, 부분범위 처리가 불가능해 진다.
인덱스 튜닝
col1 이 인덱스 선두 컬럼일 때, in (list) 방식이 유리하다.
where col1 <> 3 => where col1 in (0, 1, 2, 4, 5, 6)
where col1 between 'A' AND C => where col1 in ('A', 'B', 'C')
col2 가 인덱스 후행 컬럼일 때는 in(list) 보다 filter 방식이 유리하다.
where col1 = :val1 and col2 in(0, 1, 2, 4, 5, 6) => where col1 = :val1 and col2 <> 3
선두컬럼 "or" 조건은 union all 로 처리하는게 유리하다.
select /*+ use_concat */ from where col1 like 'A%' or col1 like 'B%'
후행컬럼 or 조건은 union all 로 처리하는게 불리하다.
select /*+ no_expand */ from where col1 = 'ABC' and ( col2 like 'A%' or col2 like 'B%' )
LIKE 검색
like :val || '%'
시작값으로 조회할때만 index range scan 이 가능하다. null 허용 컬럼에서 null 값을 찾을때는 like '%' 로 변환되어, null 인 값을 못 찾게 된다. 숫자형 컬럼일때 또는 가변 컬럼일때.. 123 인 값을 찾고자 해도, 앞에 123으로 시작하는 모든 데이터를 찾게 된다. (결과의 오류) index 선두 컬럼에 대해 like 검색시 null 값으로 조회하면, 모든 index 를 찾아야 하므로, 비효율이 발생한다.
소트연산 생략
WHERE col1 = 'ABC' ORDER BY col2, col3
실행계획에 ORDER BY 가 나타나야 하지만, 인덱스에 있으면, ORDER BY 가 생략된다. 인덱스에 2번째부터 순서대로 order by 컬럼이 나와야 한다.
인덱스 구성 : col1 + col2 + col3
소트 연산이 생략되면, 부분범위 처리가 가능해진다.
MS-SQL 인덱스 힌트
PK 인덱스 사용, PK(Clustered Index) 가 없는 테이블은 테이블 풀 스캔 select * from tablename with(index(0))
PK 인덱스 사용, PK(Clustered Index) 가 없는 테이블은 오류 select * from tablename with(index(1))
인덱스명 사용 select * from tablename with(index=table_ix1) select * from tablename with(index(table_ix1))
테이블 풀 스캔 select * from where ... option( forcescan )
select * from tablename where ... option( table hint( tablename, index(table_ix1) ) )
select * from tablename with ( forceseek(table_ix1 (col1) ) )
DBMS_XPLAN.DISPLAY_CURSOR - 단일 SQL문에 대해 "실제" 수행된 실행계획
ALTER SESSION SET STATISTICS_LEVEL = ALL; SELECT * FROM Product WHERE ProductID = 1; SELECT * FROM TABLE(dbms_xplan.display_cursor(null, null, 'typical');
SELECT /*+ gather_plan_statistics */ * FROM Product WHERE ProductID = 1; SELECT * FROM TABLE(dbms_xplan.display_cursor(null, null, 'allstats last');
실행 계획의 각 단계가 반환할 것으로 예상 되는 데이터의 크기를 바이트로 나타낸 수. 이 수는 행의 수와 행의 예상 길이에 따라 결정됨
Cost
CBO가 쿼리 계획의 각 단계에 할당한 비용. CBO는 동일한 쿼리에 대해 다양한 실행 경로/계획을 생성하며 모든 쿼리에 대해 비용을 할당함
위의 실행 계획에선 전체 비용이 13인것을 알수 있음
Time
각 단계별 수행 시간
Query Block Name
SQL 문장을 Query Block이라는 단위로 나눔. inline view 와 subquery 등
Outline Data
실행 계획을 수립 하는데 필요한 내부적으로 적용된 Hint들의 목록
Predicate
조건절
Column Projection
실행 계획의 특정 단계에서 어떤 Column을 추출하는가를 의미
ADVANCED ALLSTATS LAST 포맷
Starts
말 그대로 해당 오퍼레이션이 "시작"된 횟수를 의미함 이 개념은 Nested Loops Join을 생각하시면 쉽게 이해할 수 있음 Nested Loops Join은 선행 테이블에서 읽는 로우수만큼 후행 테이블을 탐색하는 구조임 만일 선행 테이블에서 100건이 나온다면 후행 테이블을 100번 액세스하게됨 이럴 경우에 후행 테이블에서 대한 읽기 작업의 Starts 값이 "100"이 되는것
E-Rows / E-Bytes / E-Time
예측값
A-Rows / A-Time
실제 실행된 값
SQL 트레이스
- SQL Trace는 실행되는 SQL문의 실행통계를 세션별로 모아서 Trace 파일을 만듬 - SQL Trace는 세션과 인스턴스 레벨에서 SQL문장들을 분석할 수 있음 - .trc 파일로 저장되고, tkprof 유틸리티를 이용하면 분석
call
커서 상태에 따라 Parse, Execute, Fetch 세 개의 Call로 나누어 각각에 대한 통계정보를 보여준다.
Parse
커서를 파싱하고 실행계획을 생성하는 데 대한 통계
Execute
커서의 실행 단계에 대한 통계
Fetch
레코드를 실제로 Fetch하는데 대한 통계
count
Parse, Execute, Fetch 각 단계가 수행된 횟수
cpu
현재 커서가 각 단계를 수행하는 데 소요된 시간
Elapsed Time
CPU Time + Wait Time = Response시점 - Call 시점 CPU 시간에 비해 Elapsed 시간이 현저히 큰 경우는 디스크 I/O 때문이다.
disk
디스크로부터 읽은 블록 수
query
Consistent 모드에서 읽은 버퍼 블록 수
current
Current모드에서 읽은 버퍼 블록 수
rows
각 단계에서 읽거나 갱신한 처리건 수
Misses in library cache during parse
Parse 구간에서 해당 SQL을 Library Cache에서 읽지 못하고 잃어버린 횟수 값이 1이면 Hard Parse, 0이면 Soft Parse를 의미함
Optimizer mode
옵티마이저 모드
버퍼캐시 히트율
(1 - disk / (query+current)) * 100 또는 ( (query+current) -disk) / (query+current) * 100
Row Source Operation 통계 출력
Rows
각 수행단계에 출력된 row수
Cr
consistent 모드 블록 읽기
Pr(r)
디스크 블록 읽기
Pw(w)
디스크 블록 쓰기
Time
소요시간(us= microsecond)
Cost
Cost Based Optimizer(CBO)에서 예측한 비용
Size
리턴한 데이터 size(bytes)
Card
Cardinality, Cost Based Optimizer(CBO)에서 예측한 row수
현재 세션에 SQL 트레이스 거는 방법
alter session set sql_trace = true;
select 절;
=> .trc 파일이 생성됨
AutoTrace - SQL Plus에서 실행계획을 가장 쉽고 빠르게 확인해 볼 수 있는 방법
grant plustrace to scott; - plustrace 권한부여
set autotrace on - SQL 실제 수행 => SQL 실행결과, 실행계획 및 실행통계 출력
set autotrace on explain - SQL 실제 수행 => SQL 실행결과, 실행계획 출력
set autotrace on statistics - SQL 실제 수행 => SQL 실행결과, 실행통계 출력
set autotrace traceonly - SQL 실제 수행 => 실행계획 및 실행통계 출력
set autotrace traceonly explain - SQL 실제 수행 X => 실행계획 출력
set autotrace traceonly statistics - SQL 실제 수행 => 실행통계 출력
Predicate Information (identified by operation id): ---------------------------------------------------
2 - access("EMPNO"=7900)
통계
Statistics ---------------------------------------------------------- 1 recursive calls 0 db block gets 2 consistent gets 0 physical reads 0 redo size 596 bytes sent via SQL*Net to client 523 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 1 rows processed
recursive calls
사용자의 SQL문을 실행하기 위하여 수행된 SQL 문의 수
db block gets
현재 모드(current mode)에서 버퍼 캐시로부터 읽어온 블록의 총 수
consistent gets
버퍼 캐시의 블록에 대한 일관된 읽기의 요청 횟수. 일관된 읽기는 언두 정보, 즉 롤백 정보에 대한 읽기를 요구할 수도 있으며 이들 언두에 대한 읽기도 계산됨
physical reads
물리적으로 데이터 파일을 읽어 버퍼 캐시에 넣은 횟수
redo size
해당 문이 실행되는 동안 생성된 리두의 전체 크기를 바이트 단위로 나타낸 수
byte sent via SQL*Net to client
서버로부터 클라이언트에 전송된 총 바이트 수
byte recevied via SQL*Net from client
클라이언트로부터 받은 총 바이트 수
SQL*Net roundtrips to/from client
클라이언트로(부터) 전송된 SQL*Net 메시지의 총 수. 다중 행 결과 집합으로부터 꺼내오기 위한 왕복을 포함함
sorts(memory)
사용자의 세션 메모리(정렬 영역)에서 수행된 정렬 sort_area_size 데이터베이스 매개변수에 의해 제어됨
sorts(disk)
사용자의 정렬 영역의 크기를 초과하여 디스크(임시 테이블 영역)를 사용하는 정렬
rows processed
수정되거나 select 문으로부터 반환된 행
MS-SQL Server
트레이스 확인 방법
set statistics profile on set statistics io on set statistics time on
- 구문분석 및 컴파일 시간 - 논리직/물리적 읽기 수 - 각 오퍼레이션 단계별 실행 횟수
set statistics profile on - 실제 실행계획 표시
Rows : 각 연산자에서 만든 실제의 행 수를 보여줍니다. Executes : 각 연산자가 몇 번 실행이 되었는지 보여줍니다 StmtText : 세부적으로 어떤 실행이 있었는지를 보여주거나, 실제로 실행된 쿼리를 보여줍니다 Argument : 수행되는 작업의 추가정보를 제공합니다. TOP 절의 행 수나, Group By 조건, Where 조건, Index Seek 혹은 Scan사항 등
set statistics io on - I/O 통계 표시
테이블 'emp'. 스캔 수 1, 논리적 읽기 28, 실제 읽기 0, 페이지 서버 읽기 0, 미리 읽기 읽기 0, 페이지 서버 미리 읽기 읽기 0, lob 논리적 읽기 0, lob 실제 읽기 0, lob 페이지 서버 읽기 0, lob 미리 읽기 읽기 0, lob 페이지 서버 미리 읽기 읽기 0.
set statistics time on - 시간 통계 표시
SQL Server 구문 분석 및 컴파일 시간: CPU 시간 = 0ms, 경과 시간 = 0ms.
(100개 행이 영향을 받음)
SQL Server 실행 시간: CPU 시간 = 0ms, 경과 시간 = 222ms
SET SHOWPLAN_ALL ON 또는 SET SHOWPLAN_TEXT ON - 예상 실행계획 표시
쿼리별로 실행계획에 나타나는 형태
SELECT distinct / UNION HASH (UNIQUE)
GROUP BY HASH (GROUP BY)
ORDER BY SORT (ORDER BY)
집계함수 SUM(), COUNT() SORT (AGGREGATE)
윈도우함수 SUM() over(partition by xx) WINDOW (SORT)
ROWNUM 사용시 COUNT (STOPKEY)
Response Time Analysis 방법론 - 세션 또는 시스템 전체에 발생하는 병목 현상과 그 원인을 찾아 문제를 해결하는 방법 - CPU time과 Wait time을 각각 break down하면서 서버의 일량과 대기 시간을 분석
Response Time = Servic Time + Wait Time 또는 Response Time = CPU time + Queue Time
AWR (Automatic Workload Repository) 보고서 - DB 의 상태를 진단하는 정보 - DBA에게 데이터베이스 실행 시간과 관련된 스냅샷과 상세한 정보를 제공 - Statpack 을 업그레이드 해서 개발 되었다.
DB 대기 이벤트 및 통계 정보 - 시스템 통계 정보 - 데이터베이스 부하 정보 - SQL 수행 정보 - 활동 세션 정보
Dirty 블록을 데이터 파일에 기록하기 전에, Redo 엔트리를 Redo 로그 파일에 기록했음이 보장되야 한다.
메모리 영역
SGA (System Global Area) - 공유 메모리 그룹, 모든 서버 및 백그라운드 프로스세에 공유된다. - Shared Pool, 데이터베이스 버퍼캐시, Redo 로그 버퍼, 딕셔너리 캐시
PGA (Program Global Area) - 비공유 메모리 구조 그룹 - 한 프로세스 혹은 스레드의 개별적인 메모리 공간 - 정렬 공간 (Sort Area), 세션 정보 (Session Information), 커서 상태 정보(Cursor State), 변수 저장 공간 (Stack Area)
UGA (User Global Area) - 로그온 정보나 세션이 필요로 하는 정보를 저장하고 있는 세션 메모리 - Shared Server의 경우 SGA 에 존재 - Dedicated Server일 경우 PGA 내부에 존재
CGA (Call Global Area) - 데이터베이스 콜(parse, execute, fetch)에 필요하고, 끝나면 해제되는 데이터를 담고 있다.
Single Block I/O - 기본적인 인덱스 사용 시 단일 블록으로 읽어들인다.
Multi Block I/O - 인접한 블록을 함께 읽어 들인다. - 한 익스텐트 경계를 넘지는 못한다. - Index Fast Full Scan, Table Full Scan 에서 다중 블록으로 읽어들인다.
Direct Path I/O 는 버퍼 캐시를 경유하지 않는다. (병렬 프로세스로 테이블을 Full Scan)
LRU 알고리즘 - 가장 오래전에 사용된 데이터 블록을 버퍼캐시에서 밀어내는 알고리즘 - 사용빈도가 높은 데이터 블록이 버퍼캐시에 오래 남아 있도록 한다.
Shared Pool
빠른 Parsing을 위해 Hard Parsing을 줄이고 Soft Parsing의 비율을 높여 Oracle Database의 성능을 높히는 것
Soft Parsing
- Library Cache에 저장되어 있는 SQL문을 수행하여 Parse 작업없이 기존에 있는 실행계획대로 실행
Hard Parsing
- Parsing 작업을 수행하여 SQL문 확인 및 실행계획을 새로 생성함
Library Cache
- Parsing 정보를 저장하는 메모리
- Oracle Instance SGA Shared Pool 영역에 존재 - SQL 과 실행계획, PL/SQL 프로그램(프로시저, 함수, 트리거 등) 캐싱
CASE 문 - case expr when 1 then '참' else '거짓' end : expr 이 1이면 참 아니면 거짓 - case when expr <= 10 then '참' else '거짓' end : expr 이 10 이하면 참, 아니면 거짓
GROUP BY / HAVING - 집계함수 Count 에서 데이터가 없으면 0 이 나오지만, having 절에 의해 데이터가 없으면, no records 이다.
ORDER BY - 기본정렬은 오름차순 ASC 이고, 내림차순은 DESC 이다. - 오라클은 NULL 이 가장 큰 값으로 간주하여, 오름차순에서 가장 아래에 위치한다. - MSSQL 은 NULL 이 가장 작은 값으로 간주하여, 오름차순에서 가장 위에 위치한다.
SELECT 실행순서
순서
쿼리
5
SELECT
1
FROM
2
WHERE
3
GROUP BY
4
HAVING
6
ORDER BY
TOP N 쿼리
MSSQL select top 10 * from order by col1
Oracle select * from ( select * from order by col1 ) where rownum <= 10
INNER JOIN - 조건에 일치하는 행만 반환한다. from A inner join B on A.col1 = B.col1 from A join B on A.col1 = B.col1 from A, B where A.col1 = B.col1
- using 사용 from A join B using(col1)
OUTER JOIN - Join 조건에 일치하는 행과, 일치하지 않는 행도 반환한다.
left outer join
from A left outer join B on A.col1 = B.col1 from A left join B on A.col1 = B.col1 from A, B where A.col1 = B.col1(+)
- 조건에 일치하는 행과 왼쪽 테이블 기준으로 오른쪽에는 일치하지 않는 행도 반환한다. - A, B 테이블에 일치하는 데이터와, A에만 있고 B에는 없는 행도 반환
right outer join
from A right outer join B on A.col1 = B.col1 from A right join B on A.col1 = B.col1 from A, B where A.col1(+) = B.col1
- 조건에 일치하는 행과 오른쪽 테이블 기준으로 왼쪽에는 일치하지 않는 행도 반환한다. - A, B 테이블에 일치하는 데이터와, B에만 있고 A에는 없는 행도 반환
full outer join
from A full outer join B on A.col1 = B.col1
- 조건에 일치하는 행과 양쪽 테이블의 조건에 일치하지 않는 행도 반환한다. - A, B 테이블에 일치하는 데이터와, A에만 있고 B에는 없는 행, B에만 있고 A에는 없는 행도 반환
NATURAL JOIN - A, B 테이블에 같은 이름의 모든 컬럼이 자동으로 연결된다. - SELECT 절에 EMP.col 테이블명을 지정해서 쓰면 오류가 발생한다.
from A natural join B
CROSS JOIN - join 조건이 없는 경우, 테이블간에 모든 데이터 조합으로 행을 반환한다. - M * N 의 카티션 행 조합
from A cross join B
집합 연산자
UNION - 합집합, 중복데이터는 제외
UNION ALL - 합집합, 중복데이터 유지
INTERSECT - 교집합, 결과에서 중복데이터는 제외
EXCEPT (오라클 MINUS) - 차집합 , 결과에서 중복데이터는 제외 - A 에서 B 의 데이터를 제외한 결과
계층형질의
START WITH CONNECT BY
조직도와 같은 Tree 구조의 데이터를 조회할 때 사용한다.
가상컬럼 level : 해당 행이 ROOT 데이터이면 1, 하위 데이터이면 2, 그 하위이면 +1 씩 증가 connect_by_isleaf : 해당 행이 LEAF 데이터 이면 1, 아니면 0 connect_by_iscycle : 중복 참조이면 1, 아니면 0 : 현 데이터의 하위 데이터가, 하위 데이터의 현데이터로 지정한 경우, 무한 루프에 빠지게 된다.
select level, ( lpad(' ', 4 * (level-1)) || empno ) as empno , connect_by_isleaf as isleaf from emp start with empno is null connect by prior mgr = empno;
start with 조건에는 root 노드를 지정하고 connect by 에는 하위노드를 찾는 방법을 지정한다.
prior 에 지정된 컬럼에서 상대편 컬럼으로 찾아간다.
CONNECT BY PRIOR 하위 컬럼 = 상위 컬럼 : 상위 -> 하위로 가는 순방향 전개 CONNECT BY PRIOR 상위 컬럼 = 하위 컬럼 : 하위 -> 상위로 가는 역방향 전개
ORDER SIBLINGS BY - order by 와 같이 정렬을 수행하나, 같은 level 간의 정렬 순위를 지정한다.
NOCYCLE - connect by NOCYCLE prior mgr = empno - 데이터 입력실수로, 이전에 전개된 데이터가 다시 나타나는 현상이 발생하면 무한루프에 빠지게 된다. - 이전에 전개된 데이터가 다시 나오면 전개를 멈추는 옵션.
서브쿼리 - 괄호로 묶인 SELECT 절
단일행 서브쿼리 - 결과행이 1개만 나오는 서브쿼리 - select 쿼리 안에 단일 값 조회시 사용되거나, wehere 절의 비교 연산자 등에 온다.
다중행 서브쿼리 - 결과행이 n 개 나오는 서브쿼리 - from 절의 쿼리에 오거나, where 절의 in , all, any, some, exists 등에 온다.
뷰(VIEW)
독립성 - 테이블구조가 변경되어도, 뷰를 사용하는 응용프로그램은 변경할 필요가 없다. 편리성 - 복잡한 질의나 자주 사용하는 질의를 뷰로 만들면, 쿼리가 간단해 진다. 보안성 - 숨기고 싶은 정보는 제외하고, 정보(컬럼) 를 제공할 수 있다.
그룹 함수
ROLLUP - 지정된 컬럼의 소계와 합계를 구하는 함수 - 인수의 순서에 따라 결과가 달라진다.
group by rollup(dname, job) - (dname, job) 별 소계, dname 별 소계, 전체 합계를 구한다.
CUBE - 가능한 모든 조합의 소계와 합계를 구한다. - 인수의 순서는 상관이 없다.
group by cube(dname, job) - (dname, job) 별 소계, dname 별 소계, job 별 소계, 전체 합계를 구한다.
GROUPING SETS - 소계 / 합계를 직접 선택하여 지정할 수 있는 함수 - () 또는 null 을 쓰면 전체 합계를 구한다.
group by grouping sets( (dname, job), (dname), () ) - 이렇게 쓰면 group by rollup(dname, job) 과 동일하다.
group by grouping sets( (dname, job), (dname), (job), () ) - 이렇게 쓰면 group by cube(dname, job) 과 동일하다.
GROUPING 함수 - select 절에서 해당 행이 소계에 사용된 행인지 여부를 판단할 때 사용한다.
select (case when grouping(job) = 1 then 'JOB합계' else job end ) - 부서별 모든 소계행인경우, JOB합계로 표시하고, 아닌경우 job 명칭을 표시한다.
Window 함수
partition by
sum(sal) over(partition by deptno)
sum(sal) over(partition by deptno group by emp range between unbounded preceding and current row)
rows - 물리적인 결과 행의 수를 지정한다.
range - 논리적인 값에 의한 범위를 지정한다.
n preceding - n 개 앞의 행
unbounded preceding - 첫번째 행
n following - n 개 뒤의 행
unbounded following - 마지막 행
current row - 현재 행
RANGE UNBOUNDED PRECEDING SUM(sal) OVER(partition by mgr order by sal range unbounded preceding) = RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW 와 동일하다. - 파티션 내에서 첫번째 행 부터 현재 행까지의 합계 즉 누적합을 표시
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING SUM(sal) OVER(partition by mgr order by sal rows between 1 preceding and 1 following) - 현재행+앞에1행+뒤에1행 합계
RANGE BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING SUM(sal) OVER(partition by mgr order by sal range between current row and unbounded following) - 현재행부터 마지막 행까지 합계
CTE(Common Table Expression) - 일시적인 결과 세트를 정의하고 이를 나중에 쿼리에서 참조할 수 있게 하는 방법
CTE와 서브쿼리의 차이점 - 가독성: CTE는 복잡한 쿼리를 여러 부분으로 나누어 가독성 높여준다. - 재사용성: CTE는 동일한 쿼리 내에서 여러 번 재사용 가능 - 성능: CTE와 서브쿼리의 성능 차이는 데이터베이스 시스템과 쿼리의 복잡도 따라 다름 - CTE는 재귀적 쿼리에 유리
WITH kor_restaurants AS ( SELECT * FROM restaurants WHERE rest_type = 'kor' )
재귀적 CTE
WITH cte (n) AS ( SELECT 1 UNION ALL SELECT n+1 FROM cte WHERE n < 5 )
NTILE - 전체건수를 지정한 건수로 N등분
LAG - N개 앞의 행 값 조회
LEAD - N개 뒤의 행 값 조회
NULL 값 - 아직 정해지지 않은 미지의 값
NULL 비교는 IS NULL / IS NOT NULL 을 사용한다.
where in (list) 에서 list 에 NULL 이 있으면, 실제 NULL 인 데이터는 제외 된다. - where ID in (1, 2, NULL) : ID 가 NULL 인 데이터는 제외되고, 1이나 2인 데이터만 조회된다.
where not in (list) 에서 list 에 NULL 이 있으면, 전체가 false 가 되어, 결과집합이 없다.
- where ID not in (1, 2, NULL) : ID <> 1 and ID <> 2 and ID <> NULL => and 조건에 의해 하나라도 false 면 모두 false 이다.
NULL 과의 연산은 NULL 이 된다. NULL + 10 => NULL
집계함수에서 NULL 값이 있다면 제외된다. - SUM, COUNT 등
순위
ROW_NUMBER()
1,2,3 순차적으로 순위를 매김
RANK()
1,1,1,4,5,6 동일 값이면 같은 순위를 갖고, 다음순위는 건너뜀.
DENSE_RANK()
1,1,1,2,3,4 동일 값이면 같은 순위를 갖고, 다음순위로 넘어감.
PIVOT - 행을 열로 변환한다.
SELECT * FROM 테이블 PIVOT ( 그룹합수(집계컬럼) FOR 피벗컬럼 IN (피벗컬럼값 AS 별칭 ... )
SELECT job, d1, d2, d3 FROM emp PIVOT ( SUM(sal) FOR deptno IN ('10' AS d1, '20' AS d2, '30' AS d3) )
UNPIVOT - 열을 행으로 변환한다.
SELECT * FROM 테이블 UNPIVOT ( 컬럼별칭(값) FOR 컬럼별칭(열) IN (피벗열명 AS '별칭', ... )
SELECT col_nm, col_val FROM emp UNPIVOT ( col_val FOR col_nm IN (col1, col2, col3) )
정규표현식
REGEXP_LIKE - Like 연산과 유사하여 정규식 패턴을 검색
REGEXP_LIKE(srcstr, pattern[,match_option])
SELECT A.* FROM REG_TEST A WHERE REGEXP_LIKE(A.DATA, '[0-9]') ;
SELECT A.* FROM REG_TEST A WHERE REGEXP_LIKE(A.DATA, '[[:digit:]]');
숫자가 포함된 데이터 찾기
SELECLT A.* FROM REG_TEST A WHERE REGEXP_LIKE(A.DATA, '^[[:punct:]]*$');
using (StreamReader reader = new StreamReader(stream)) { string mesageContent = reader.ReadToEnd()
// MessageSend(messageContent); } }
이렇게 해서 테스트를 해보면, 실시간 알림이 안오고, 한참 있다가 알림이 오게 되는걸 볼 수 있다.
이유는, 윈도우 시스템 (NTFS) 이 파일에 쓰기 버퍼를 사용하기 때문이다.
즉, 일정한 시간이 지나야 버퍼를 실제 물리적인 파일에 저장하기 때문이다.
윈도우 시스템이 실시간으로 파일을 변경하도록 하기 위해서는
로그파일을 Open / Close 를 주기적으로 해주면 된다.
try { // NTFS 의 파일 캐싱으로 인해 로그파일이 변화를 watcher 가 즉시 탐지하지 못한다. // 파일 변화를 즉시 감지하기 위해 open 모드로 읽고 닫기를 한다. File.Open(this.logFullPath, FileMode.Open).Close(); } catch (Exception) { }
try catch 를 쓰는 이유는, 로그 파일을 mysql 이 잡고 있기 때문에, Exception 이 발생하기 때문이다.
하지만, 이렇게 주기적으로 해당 파일을 건들어 주면, 윈도우 시스템이 버퍼를 파일로 저장하는 효과를 얻을 수 있어,
실시간 파일 감시가 가능해지기 때문이다.
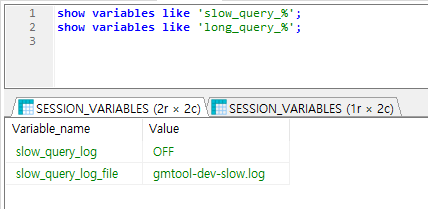
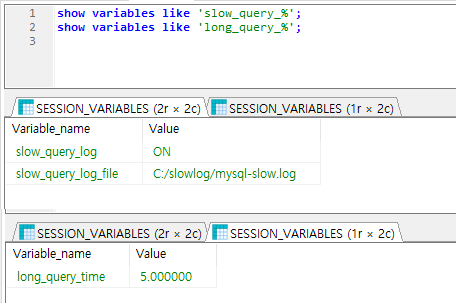
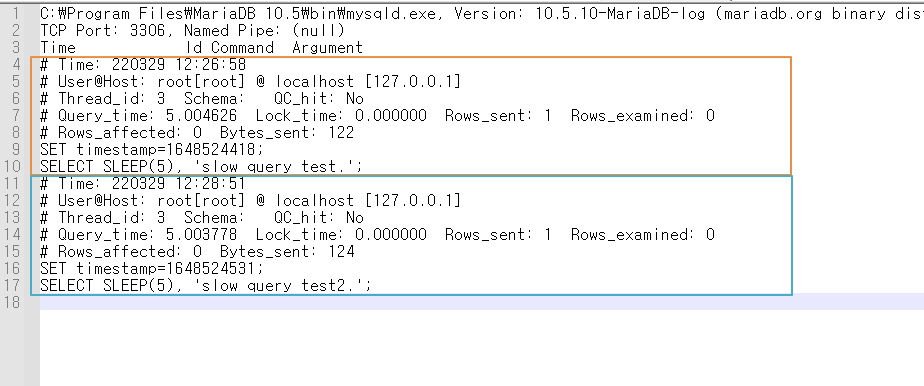
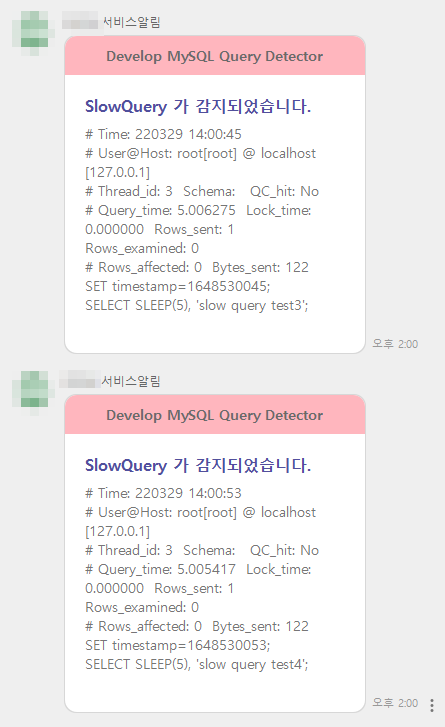
이렇게 해서, 프로그램을 돌려놓고, slow query 를 발생해보면, 알림이 오는것을 확인할 수 있다.
네이버웍스 메신저르 알림을 보낸 샘플이다.
주의할점은 슬로우 쿼리는 트랜잭션 단위의 쿼리가 아니라, 쿼리문장 단위로 탐지를 한다는 점이다.