3과목. SQL 고급활용 및 튜닝
1. SQL 수행 구조
2. SQL 분석 도구
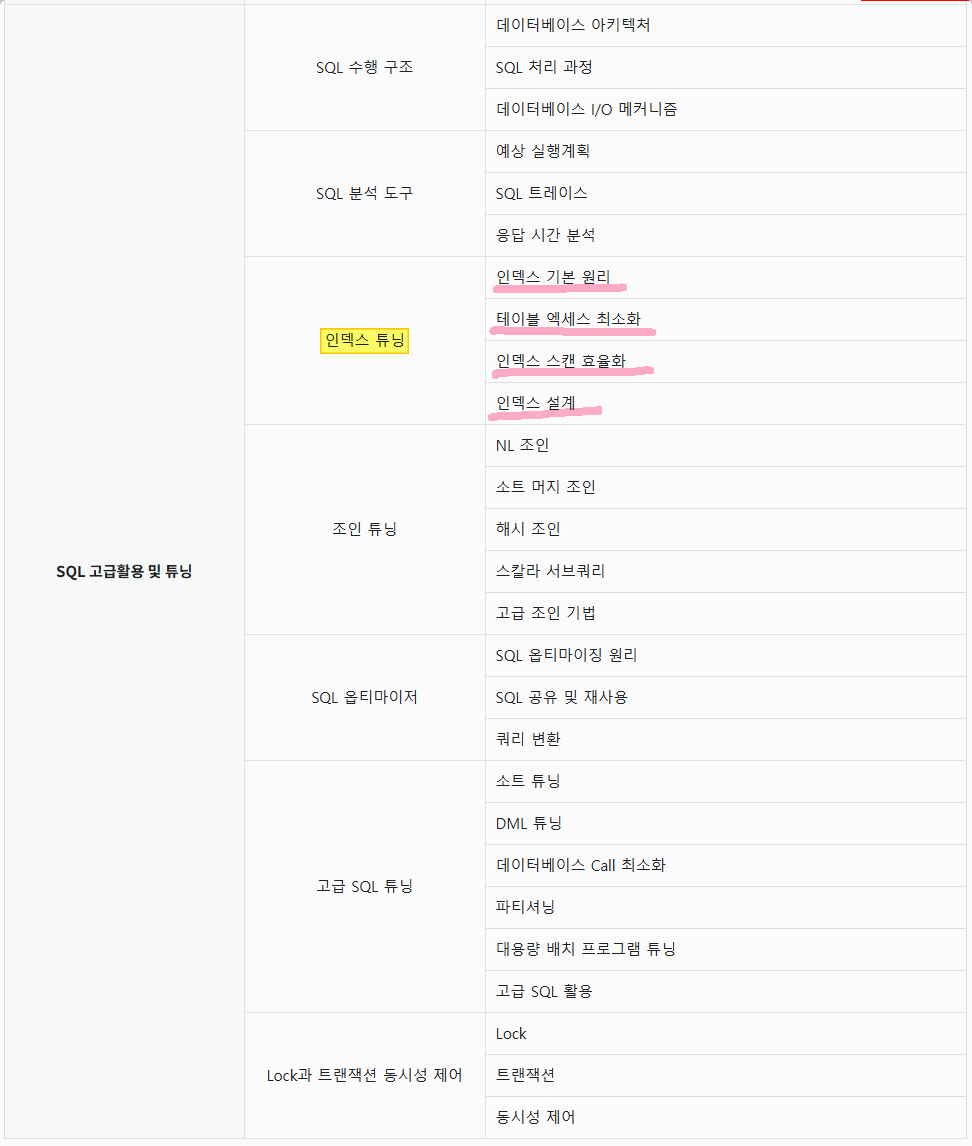
3. 인덱스 튜닝
4. 조인 튜닝
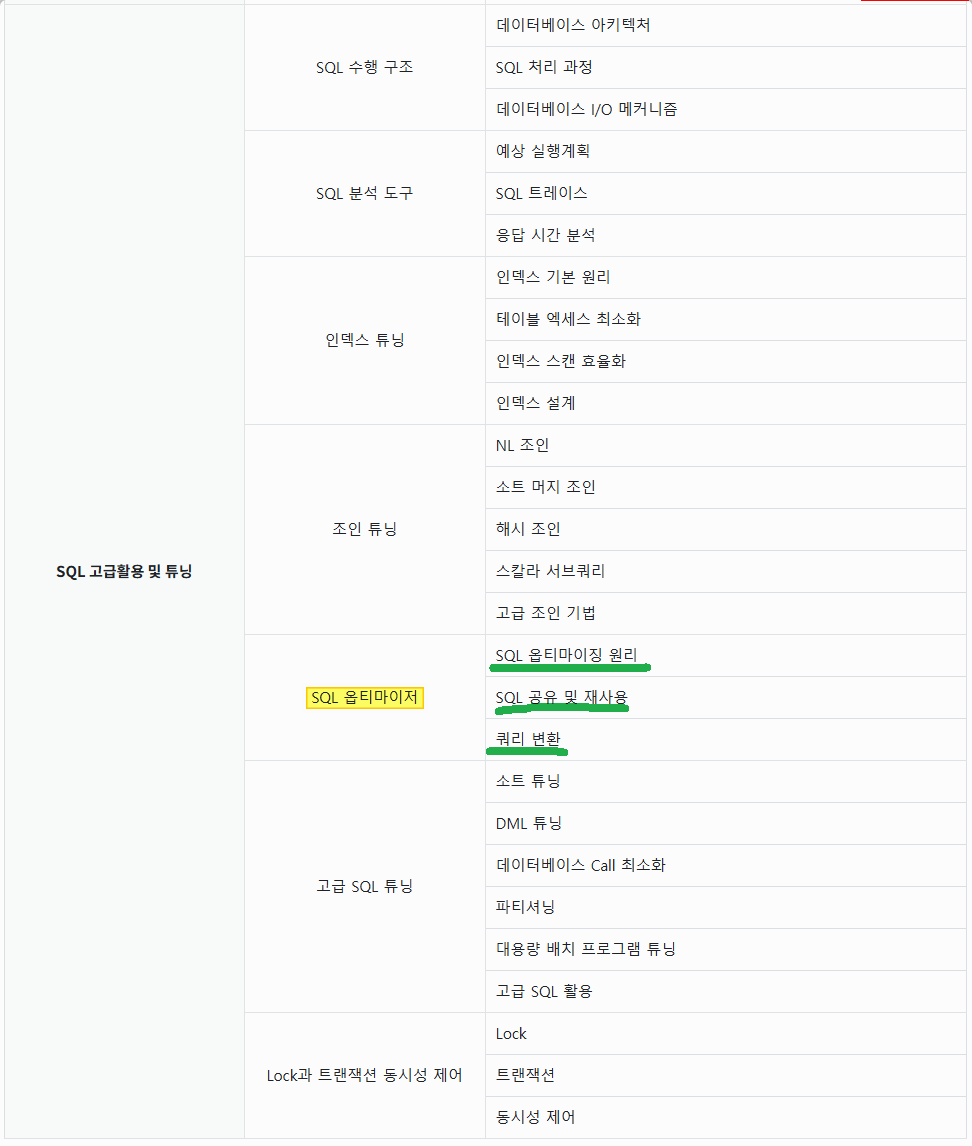
5. SQL 옵티마이저
6. 고급 SQL 튜닝
7. Lock과 트랜잭션 동시성 제어

Lock
- 같은 자원을 액세스 하는 다중 트랜잭션 환경에서 데이터베이스의 일관성과 무결성을 유지하면서 순차적인 진행을 보장하는 직렬화 수단
공유 Lock (Shared Lock)
- 데이터를 읽기 위해 사용하는 Lock
- 한 자원에 대해 같은 공유 Lock 끼리는 여러개 설정이 가능하다. (동시에 읽기 가능)
- 배타적 Lock 과는 동시 진행 불가.
배타적 Lock (Exclusive Lock)
- 데이터를 변경하고자 할 때 사용하는 Lock
- 트랜잭션이 종료될때까지 유지되며, 다른 공유 Lock / 배타적 Lock 이 동시에 설정 불가하다.
블로킹 (Blocking)
- Lock 경합으로, 다른 트랜잭션에서 Lock 이 걸려서, 대기하고 있는 상태
교착상태 (Deadlock)
- 두개의 세션이 각각 Lock 을 설정한 리소스를 서로 액세스 하려고 블로킹 상태에 있는 상태
SET TRANSACTION ISOLATION LEVEL
{ READ UNCOMMITTED
| READ COMMITTED
| REPEATABLE READ
| SNAPSHOT
| SERIALIZABLE
}
READ UNCOMMITTED
- 다른 트랜잭션에 의해 수정되었지만 아직 커밋되지 않은 행을 문이 읽을 수 있도록 지정
READ COMMITTED
- 다른 트랜잭션에 의해 수정되었지만 아직 커밋되지 않은 데이터를 문이 읽을 수 없도록 지정
- MS-SQL Select : Row 레코드를 읽는 동시에 Lock 을 획득하고, 다음 레코드로 이동하는 순간 Lock 이 해제된다.
REPEATABLE READ
- 다른 트랜잭션에 의해 수정되었지만 아직 커밋되지 않은 데이터를 문이 읽을 수 없도록 지정하고 현재 트랜잭션이 완료될 때까지 현재 트랜잭션이 읽은 데이터를 다른 트랜잭션이 수정할 수 없도록 지정
- MS-SQL Select : Row 레코드를 읽는 동시에 Lock 을 획득하고, 최종커밋 또는 롤백 하는 순간 Lock 이 해제된다.
SNAPSHOT
- 트랜잭션의 문이 읽은 데이터가 트랜잭션별로 트랜잭션을 시작할 때 존재한 데이터 버전과 일관성이 유지되도록 지정
SERIALIZABLE
- 가장 엄격한 격리수준. 트랜잭션이 완료될 때까지 다른 사용자는 그 영역에 해당되는 데이터에 대한 수정 및 입력이 불가능
트랜잭션의 4가지 특징 (ACID)
| 원자성 (Atomicity) | 분해가 불가능한 업무의 최소단위로, 전부 처리되거나, 전부 처리되지 않아야 한다. |
| 일관성 (Consistency) | 트랜잭션 결과로 데이터베이스 상태가 모순되지 않아야 한다. |
| 격리성 (Isolation) | 트랜잭션의 중간 값에 다른 트랜잭션이 접근할 수 없다. |
| 영속성 (Durability) | 트랜잭션의 결과가 데이터베이스에 영속적으로 저장된다. |
Lock Escalation
- 로우 레벨 Lock 이 페이지, 익스텐트, 테이블 레벨 Lock 으로 점점 확장되는 것.
- 오라클은 로우 속성으로 Lock 을 관리하므로, Lock Escalation 이 발생하지 않는다.
동시성
- DML 수행 시, ROW 단위로 배타적 Lock 이 걸린다.
오라클
- DML 문이 실행되는 동안 해당 ROW 는 update/delete 불가하다. select 는 가능.
MS-SQL
- DML 문이 실행되는 동안 해당 ROW 는 select/update/delete 불가하다.
- 제약조건이나 unique 인덱스 설정이 없으면, insert 하는 동안에 다른 insert 도 가능하다.
- insert 하는 동안에, 다른 select 절이 full scan 하게 되면, select 도 동시에 실행이 불가능하다. => index range 스캔을 하게 되면 select 가능.
TX Lock (Transaction Lock)
- 행 수준(Row-level) 잠금
TM Lock(Table Lock)
- 테이블 잠금, 테이블에 대한 구조적 변경(DDL) 이나, DML(데이터 조작 언어) 작업 시 데이터 무결성을 보장
- SELECT for UPDATE 문 에서도 TM Lock 이 설정된다.
이상현상
Dirty Read
- 다른 트랜잭션이 변경중인 데이터를 읽어서 사용했는데. 다른 트랜잭션이 rollback 되는 경우.
Non-Repeatable Read
- 한 트랜잭션 내에서 값을 두번이상 읽어서 사용하는 중간에 다른 트랜잭션이 해당값을 변경(update / delete) 해서, 값이 달라지는 경우.
Phantom Read
- 한 트랜잭션 내에서 일정 범위의 값을 두번이상 읽어서 사용하는 중간에 다른 트랜잭션이 새로운 값을 추가(insert) 함으로써, 처음 읽을때 없던 값이 나중에 생긴 경우.
비관적 동시성 제어
- 데이터를 읽는 시점부터 Lock 을 설정한다.
낙관적 동시성 제어
- 데이터를 읽는 시점에 Lock 을 설정하지 않는다.
- 다만, 읽은 데이터를 다시 읽거나, 수정하는 시점에 반드시 변경 여부를 확인한다.
SELECT FOR UPDATE
- 해당 행을 읽으면서, 하단에서 변경하기 위해 lock 을 건다.
- Lock 이 걸린 행을 만나면, Lock 이 해제될 때까지 무작정 기다린다.
SELECT FOR UPDATE WAIT n
- Lock 이 걸린 행을 만나면, n 초간 기다리고, 해제되지 않으면 SELECT 문 전체를 종료한다. (Exception)
SELECT FOR UPDATE NOWAIT
- Lock 이 걸린 행을 만나면, 즉시 SELECT 문 전체를 종료한다. (Exception)
snapshot too old 에러
- Table Full Scan 및 해시 조인을 사용하면 에러를 줄일 수 있다.
- 데이터 조회시 Order by 를 사용하면 에러를 줄일 수 있다.
- 튜닝을 통해 줄일수는 있어도 완전히 해소하기는 어렵다.
- Undo 영역의 크기를 증가시키고, commit 을 자주 수행하지 말아야 한다.
'데이터베이스' 카테고리의 다른 글
| [SQLP 요점정리] 3과목. SQL 고급활용 및 튜닝 - 6. 고급SQL튜닝 (1) | 2025.03.06 |
|---|---|
| [SQLP 요점정리] 3과목. SQL 고급활용 및 튜닝 - 5. SQL옵티마이저 (0) | 2025.03.05 |
| [SQLP 요점정리] 3과목. SQL 고급활용 및 튜닝 - 4. 조인튜닝 (0) | 2025.03.04 |
| [SQLP 요점정리] 3과목. SQL 고급활용 및 튜닝 - 3. 인덱스튜닝 (0) | 2025.03.03 |
| [SQLP 요점정리] 3과목. SQL 고급활용 및 튜닝 - 2. SQL 분석도구 (0) | 2025.03.02 |