SQLP : 제3과목은 SQL 고급활용 및 튜닝 이다.
3과목. SQL 고급활용 및 튜닝
1. SQL 수행 구조
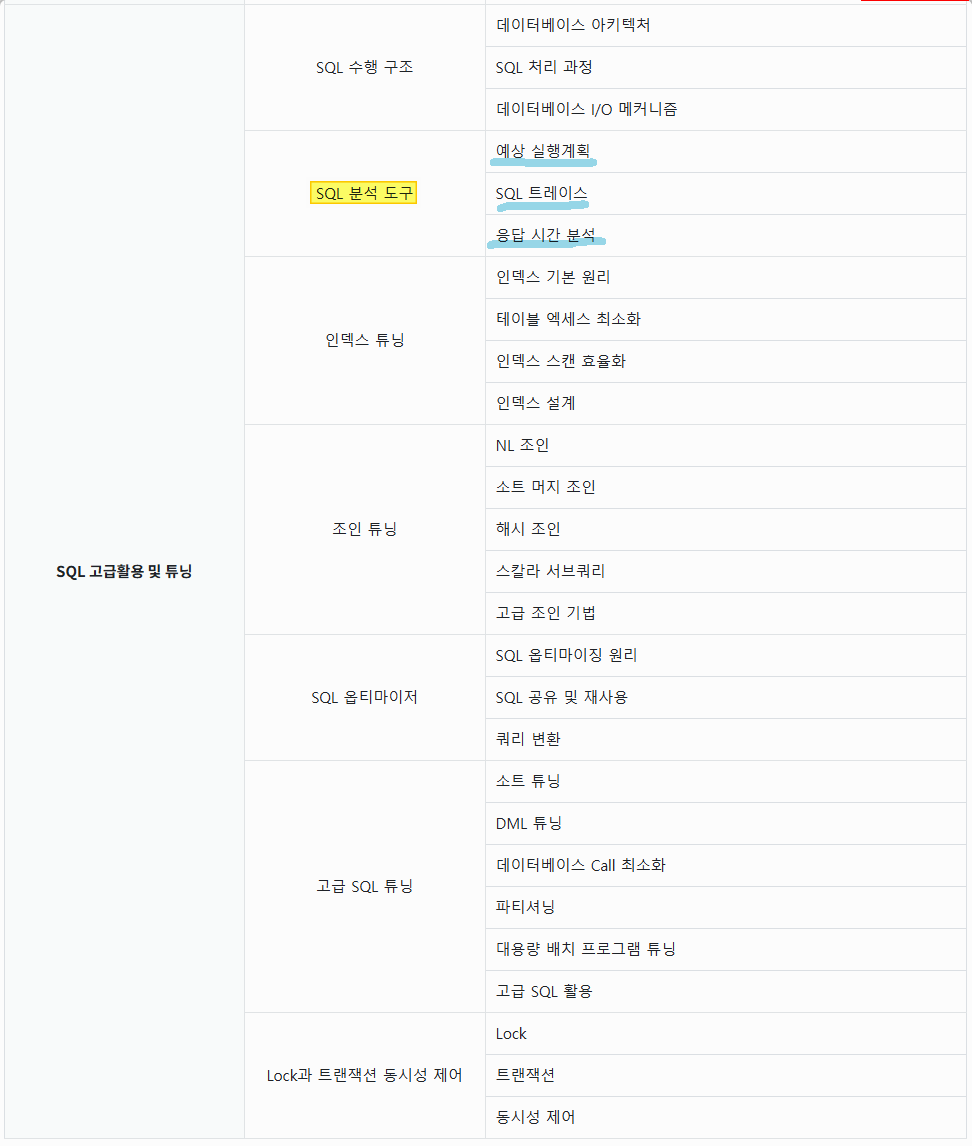
2. SQL 분석 도구
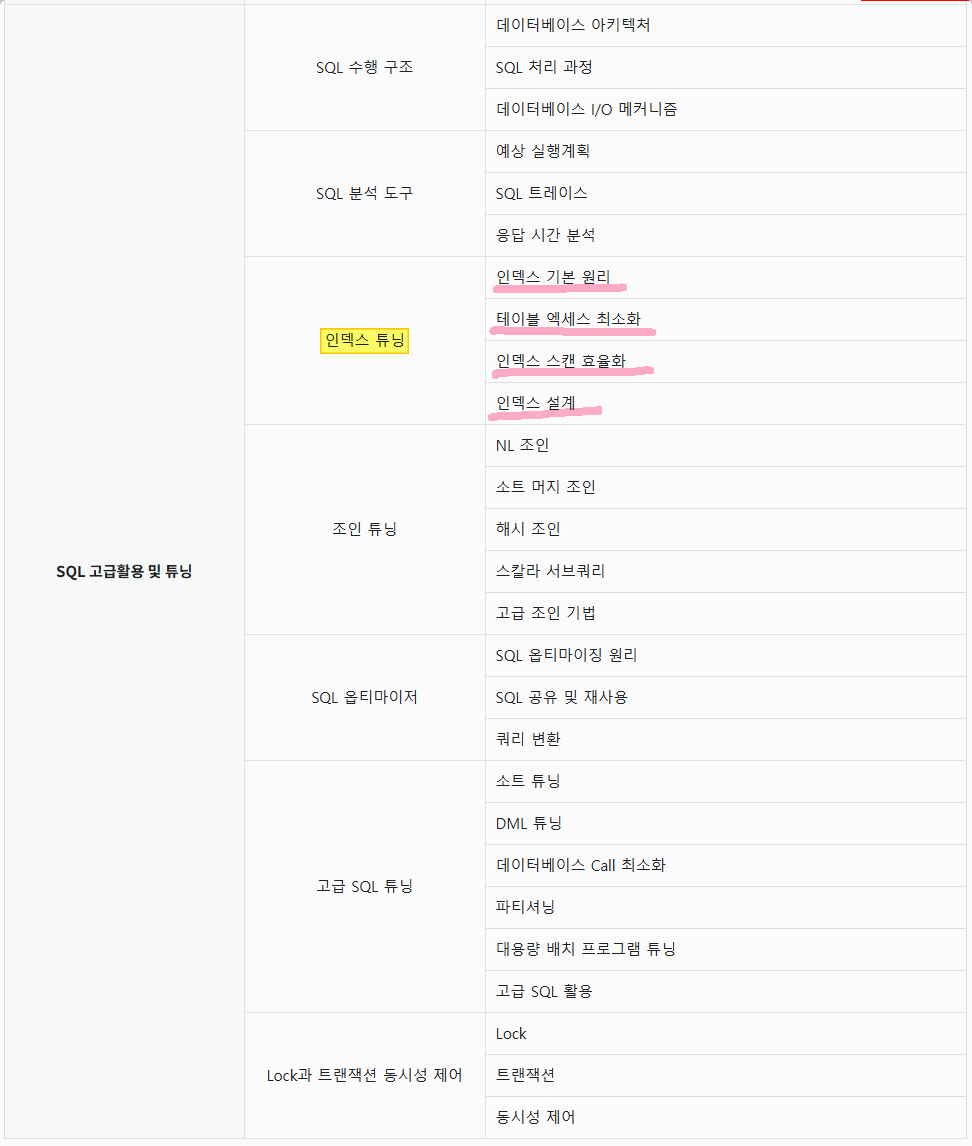
3. 인덱스 튜닝
4. 조인 튜닝
5. SQL 옵티마이저
6. 고급 SQL 튜닝
7. Lock과 트랜잭션 동시성 제어

NL(Nested-Loop) 조인
- 중첩된 Loop 로 조인을 하는 구조이다.
| for( ... ) { for( ...) { ... } } |
- 랜덤 액세스 위주의 조인 방식 : 대량 데이터에서 불리
- 소량데이터 조인시 유리
- DB버퍼캐시에서 읽으므로, 블록에 래치 획득 및 체인 스캔 과정을 거친다. : 대량 데이터에서 불리
- 인덱스를 이용한 조인으로, 인덱스 구성 전략에 의해 성능이 크게 달라진다.
- 후행 테이블의 인덱스 효율성이 중요하다.
- 소량 데이터에 유리, OLTP 시스템에 적합
- 한 레코드씩 순차적으로 진행 : "부분범위 처리"가 가능
- 조인 대상 레코드가 많아도, ArraySize 에 해당하는 최초 n 건을 빠르게 출력 가능
소트머지조인
- 실시간으로 인덱스를 생성한다.
- 첫번째 집합은 조인컬럼에 인덱스가 있으면 인덱스를 사용하고, 없으면 PGA 영역에 저장한다.
- 두번째 집합은 정렬해서 PGA 영역에 저장한다.
- 조인조건이 = 이 아닐때, 조인조건이 없을때도 사용가능하다.
- 버퍼영역이 아닌 PGA 영역에서 조회하므로, 대량 데이터에서 NL 조인보다 빠르다. : 래치 획득 과정이 없어서
Hash 조인
- 작은 집합을 읽어서 PGA 에 해시맵으로 저장한다.
- 해시맵을 사용하여 탐색하기 때문에 조인컬럼에 인덱스가 없어도 상관이 없다. : 인덱스가 성능에 영향을 주지 않음
- 소트머지조인보다 Temp테이블스페이스 사용량이 적다.
- 해시키로 조회하므로 조인 조건이 = 일때만 사용가능하다.
- 양쪽 모두 대량 데이터에서 NL 조인보다 빠르다.
- 수행빈도가 낮고, 쿼리 수행시간이 오래 걸리는 대량 데이터 조인시 유리하다.
- DW/OLAP / Batch 프로그램에 사용.
join 힌트
Oracle
| ordered /*+ ordered */ - FROM 절에 나열된 순서대로 조인 leading /*+ leading(a b c) */ - a b c 순서대로 조인 use_nl( a ) - NL 조인 힌트 use_hash( a ) - 해시 조인 힌트 use_merge( a ) - 소트 머지 조인 힌트 nl_sj - NL 세미조인 : 서브쿼리에서 사용 swap_join_inputs( a ) - a 를 build input 으로 한다. (조인의 첫번째 집합) : 해시조인에서 사용 no_swap_join_inputs ( a ) - a 를 probe input 으로 지정한다. (조인의 두번째 집합) : 해시조인에서 사용 NO_MERGE - 메인쿼리와 인라인뷰를 병합하지 말고, 인라인뷰부터 실행한다. : 인라인뷰에 함수 등이 쓰일때, 한번만 실행하도록 유도 PUSH_PRED - 메인테이블과 인라인뷰의 JOIN 시에, 조인조건을 인라인뷰 안으로 유도한다. : 인라인뷰 성능향상 NO_UNNEST - 서브쿼리를 필터 방식으로 동작하도록 처리 : 부분범위 처리가 가능해서, 해시 조인으로 처리되던거를 NL 조인으로 변경이 된다. FULL - 테이블 풀 스캔 PUSH_SUBQ - 서브쿼리가 먼저 실행되도록 제어 QB_NAME( name ) - 현재 쿼리블록의 이름을 지정 index(table index) - table 의 index 를 사용하도록 한다. index_desc - 인덱스를 역순으로 사용 index_ffs - 인덱스 Fast Full Scan 사용 use_concat - Concatenation 오퍼레이션 : OR 조건을 풀어서, Union All 조건의 쿼리로 변환한다. : or_expand no_expand - use_concat 이 작동하지 않도록 한다. : no_or_expand |
MS-SQL
| force order option( merge join) - FROM 절에 나열된 순서대로 조인 merge join option( merge join ) - 소트 머지 조인 힌트 loop join - NL 조인 힌트 inner loop join from A inner loop join B on A.col1 = B.col2 inner hash join |
스칼라 서브 쿼리
- 스칼라 서브 쿼리는 단일 값만을 반환해야 한다. (스칼라)
- 오라클에서는 서브쿼리 입출력값을 내부캐시에 저장해 두기 때문에 성능향상에 좋다.
- 서브쿼리의 효율은 코드명이나 상품명을 변환시 사용 : 카디널러티가 적은 테이블에 사용하면 좋다.
스칼라 서브쿼리 Execution Plan
- 서브쿼리가 위에 나오고, 메인쿼리가 아래에 나온다.
부분범위처리
- 조건을 만족하는 전체범위를 처리하는 것이 아니라 일단 운반단위(Array Size) 까지만 처리 하여 추출하는 처리방식
- TOP n / ROWNUM 사용 등
- 인덱스 사용이 가능하도록 조건절을 구사하고, 조인은 NL위주로 처리하고, Order By절이 있어도 소트연산을 생략할 수 있도록 인덱스를 구성 : index 의 2번째 컬럼부터 order by 컬럼을 추가
- 페이징 처리 (게시판 등)
'데이터베이스' 카테고리의 다른 글
| [SQLP 요점정리] 3과목. SQL 고급활용 및 튜닝 - 6. 고급SQL튜닝 (1) | 2025.03.06 |
|---|---|
| [SQLP 요점정리] 3과목. SQL 고급활용 및 튜닝 - 5. SQL옵티마이저 (0) | 2025.03.05 |
| [SQLP 요점정리] 3과목. SQL 고급활용 및 튜닝 - 3. 인덱스튜닝 (0) | 2025.03.03 |
| [SQLP 요점정리] 3과목. SQL 고급활용 및 튜닝 - 2. SQL 분석도구 (0) | 2025.03.02 |
| [SQLP 요점정리] 3과목. SQL 고급활용 및 튜닝 - 1. SQL 수행 구조 (0) | 2025.03.01 |